

La sovraesposizione dei dati personali online
Questo articolo fa parte di una serie dedicata all’esplorazione della sovraesposizione e del controllo sui dati personali nell’ecosistema informativo online. Partendo dalle origini di Internet come strumento di comunicazione militare, l’analisi di Marta Zeroni traccia l’evoluzione della rete fino alla sua trasformazione in un mezzo di diffusione di massa delle informazioni personali. L’avvento dei social media e la democratizzazione della condivisione online hanno portato a un’esplosione nella quantità di dati personali circolanti, creando nuove sfide per la privacy individuale.
“Lo”.
Era il 29 ottobre 1969 e, utilizzando il Teletype del professor Leonard Kleinrock, lo studente e programmatore Charlie Kline aveva appena inviato un messaggio dall’UCLA all’Istituto di Ricerca di Standford, a quasi 600 chilometri di distanza. L’intenzione era quella di scrivere “login” ma il sistema era andato in crash prima di trasmettere l’intera parola.
Si trattava della prima istanza di comunicazione mediata dal computer (c.d. CMC) e del primo utilizzo ARPANET, la rete militare per lo scambio di informazioni a distanza a cui il Governo statunitense lavorava dal 1966[1].

ARPANET: le origini militari di Internet e la diffusione nelle università
Presso l’UCLA, all’interno dell’aula 34020, è ancora presente l’elaboratore con il quale fu inviato il messaggio, “the first piece of internet equipment ever installed – a mini computer (…)” [2] . Così lo descrive Kleinrock, e tuttavia si tratta di una macchina relativamente grande – almeno per l’osservatore odierno – e soprattutto robusta; pensata, dice Kleinrock, per resistere in condizioni estremamente avverse.
Una caratteristica, questa, coerente con la finalità per cui la rete è stata creata: non la diffusione delle informazioni ma la difesa delle comunicazioni (e, di riflesso, la difesa dello stato).
Nel contesto della Guerra Fredda, ARPANET doveva collegare i centri di ricerca finanziati dal Pentagono, assicurando che la comunicazione tra gli stessi risultasse privata e sicura.
In ogni caso, gli addetti ai lavori avevano intuito il ruolo di catalizzatore che l’esperimento avrebbe presto assunto. Un anno prima che “Lo” fosse inviato, i teorici di ARPANET Joseph Licklider e Robert Taylor profetizzarono: “In a few years, men will be able to communicate more effectively through a machine than face to face” [3].
ARPANET rimase uno strumento di appannaggio delle università e dei centri di ricerca, fino al 1° gennaio 1983, quando, assieme alla Defense Data Network, adottò definitivamente il nuovo protocollo di comunicazione standardizzato sviluppatosi nel frattempo, il TCP/IP (Transfer Control Protocol/Internetwork Protocol), che permetteva ai computer di “parlare” tra loro anche su reti diverse.
La nascita di Internet: il percorso verso la diffusione di massa delle informazioni personali
Era nata Internet, ma la diffusione delle informazioni personali, alla fine del Novecento, passava ancora quasi esclusivamente attraverso i canali editoriali tradizionali, riguardando quindi perlopiù personaggi pubblici e celebrità[4]. Il cittadino comune, nel frattempo, poteva essere semmai preoccupato dalle possibili derive di forme più subdole di sorveglianza, complice l’ombra – anche solo psicologica – proiettata dalla Stasi sull’Occidente; si pensi, a titolo di esempio, ai casi schedature FIAT [5] e alle attività di intercettazione rese popolari dallo scandalo Watergate.
L’ascesa dei social media e la democratizzazione della condivisione online dei dati personali
Nel frattempo, però, internet continuava a crescere: gli internet service provider (ISP) resero possibili le reti ad accesso pubblico; con i bullettin board system e Usenet nacquero i primi strumenti di condivisioni tra gli utenti; il world wide web e l’avvento dei browser, infine, decretarono il salto di qualità: se prima internet poteva somigliare alla bacheca di sughero di una biblioteca di provincia, ora diventava uno spazio trasversalmente accessibile.
Alla fine degli anni ’90, i siti web consentivano a chiunque di condividere – quasi dialogicamente – le informazioni con un insieme definito utenti, e inoltre di propagarle verso un numero indeterminato di terzi. Da sistema di mera comunicazione la rete internet si stava evolvendo per essere, anche e soprattutto, uno strumento di diffusione [6]. È in questi anni, non a caso, che le principali testate italiane iniziano a lanciare i propri siti web (Il Corriere della Sera e Repubblica, rispettivamente, nel 1995 e 1996).
Come la rete internet degli albori, anche le piattaforme di social network – dai dismessi Friendster (2002) e My Space (2003) a Facebook (2004), primo mattone dell’impero Meta – si presentano inizialmente come sistemi chiusi, entro i quali l’utente può condividere (comunicare) con pochi e selezionati contatti. Nel giro di pochi anni, tuttavia, Facebook e gli altri social, a fronte di un aumento esponenziale dell’utenza e, non ultimo, delle possibilità di monetizzazione, aprono alle logiche della diffusione di informazioni.
I social network come nuove forme di mass media
La condivisione “privata” e i gruppi chiusi online, pur, come vedremo, non scomparendo del tutto, vanno così a sfumare nella dimensione pubblica, mentre le piattaforme iniziano a somigliare a una nuova forma di mass media, alla quale gli utenti si rivolgono anche per tenersi informati. I “vecchi” media, nel frattempo, si danno per morti [7], ma, di fatto, si trasferiscono a loro volta nelle piattaforme e inseriscono nei loro articoli web i plugin social per agevolarne la ricondivisione.
Non si crea, così, una contrapposizione netta tra vecchi e nuovi media, bensì una sorta di nuovo media ibridato, una rete d’informazione interconnessa, multiforme e sempre più estesa. La commistione è tanto più evidente oggi, alla luce di come quegli stessi giornali o tv che anni fa utilizzavano il tema delle fake news per spregiare la rete e i suoi meccanismi, sono diventati i primissimi propulsori di notizie prive di fact-checking, replicate all’infinito con titoli clickbait; una pratica, questa, non sempre priva di vittime [8].
L’utente come creatore di contenuti: quali rischi per la privacy?
Questo network tentacolare di informazione non si limita, peraltro, a inglobare i media tradizionali. Al suo interno è variamente rappresentata ogni tipo d’istanza sociale ma in particolare gli utenti, intesi come persone fisiche [9], che in questo habitat, si trovano, almeno in astratto, nella stessa posizione di partenza degli editori, con eguale possibilità di creare contenuti, disseminarli nella rete e dalla rete vederli rimbalzare sui media tradizionali, mentre i confini tra online e offline si fanno sempre più labili.
Per altro verso, è sempre più frequente che anche gli utenti che si limitano a scambiare le informazioni tra loro – in contesti più o meno chiusi, quali gruppi Facebook o Telegram, subreddit o thread di Twitter e 4chan [10] – contribuiscano esponenzialmente alla loro diffusione, con conseguenze più che concrete [11].
IoT, Big Data e la diffusione dei dati personali online
Il susseguirsi di ulteriori nuove (o vecchie e reinventate) tecnologie ha funzionato negli anni da moltiplicatore dei dati che transitano nella rete: i device IoT, le tecniche di analisi sui big data, le intelligenze artificiali che, dati alcuni (parecchi) input creano output inediti, le blockchain, fino alla prossima grande novità di cui sia starà parlando domani.
A ciò si aggiunga il rapporto di crescente interconnessione e dipendenza tra l’utente e l’interfaccia dei suoi device, la cui facilità di utilizzo e di portabilità è pari all’utilità che innegabilmente tali oggetti rivestono nei contesti professionali, personali, familiari.
La biblioteca di Babele digitale: l’universo sterminato dei contenuti online
Il giornalista Davide Piacenza, nell’indagare una prospettiva ancora diversa rispetto alla presente [12], paragona questo “mondo nuovo” alla biblioteca di Babele dell’omonimo racconto di Borges, i contenuti sono così sterminati da costituire un universo a sé stante.
Nelle sale esagonali della biblioteca, tutte collegate tra loro, ogni parete ha cinque scaffali, ogni scaffale trentadue, ogni libro quattrocento dieci pagine e così via; nella biblioteca di Babele dimora ogni possibile sapere e tuttavia, al contempo, “per una riga ragionevole, per una notizia corretta, vi sono leghe di insensate cacofonie, di farragini verbali e di incoerenze”.
“Non posso immaginare” scrive Borges. “alcuna combinazione di caratteri [dhcmrlchtdj] che la divina Biblioteca non abbia previsto”, avvicinandosi forse a rendere un’idea della quantità di contenuti che continuano a stratificarsi, nella rete.
L’aumento esponenziale dei dati generati dalle piattaforme di content sharing
Annualmente, il cloud provider Domo Inc. pubblica Data Never Sleeps, un insight sui comportamenti degli utenti online l’anno precedente. Nel 2023 è uscita la versione 10.0, con le analisi e le infografiche relative al 2022.
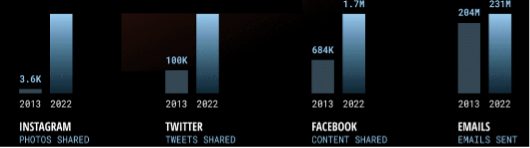
Come facilmente immaginabile, dal primo report di Domo nel 2013, i dati generati sono aumentati a livello esponenziale, in particolare nell’ambito delle piattaforme di content sharing. A fronte di uno scostamento minimo rilevato nell’utilizzo della mail, si registra, come da fig. 2, un incremento estremamente significativo per ciò che riguarda i dati condivisi dagli utenti dei principali social network.
La moderazione dei contenuti nell’era dei Big Data: sfide e implicazioni per la privacy
“Il discorso guidato dall’intervento umano” afferma il filosofo Byung-Chul Han, “impallidisce dinanzi allo sguardo divino dei Big Data”[13].
I contenuti di cui siamo spettatori in prima persona, peraltro, sono solo una parte di quelli che vedremmo in assenza dei moderatori.
L’esistenza di queste figure – ancora non del tutto soppiantate dall’intelligenza artificiale ma coadiuvate da algoritmi e software [14] – e la crescente mole di lavoro che hanno portato e portano sulle spalle con l’evolversi ipertrofico delle piattaforme di sharing, dice di per sé già molto sul potenziale dannoso connaturato alla proliferazione informativa.
“Tutto l’orrore del mondo” scrive Shoshanna Zuboff, “viene cancellato o meno in base a un flusso di lavoro razionalizzato, con decisioni prese in un istante”[15].
La figura di per sé non è un’invenzione recente: già i bulletin board systems erano moderati, così come gran parte delle community pubbliche o private, dei siti web e dei forum.
Con l’avanzare delle piattaforme, però, il lavoro dei moderatori è diventato sempre più complesso e delicato, al punto che risulta impossibile delegarlo completamente ad un’intelligenza artificiale.
AI e moderazione umana
Benché gli algoritmi giochino un ruolo senza dubbio essenziale in quest’attività [16], l’IA – addestrata con i data set generati dalle attività degli stessi moderatori – può essere utilizzata per ora solo in chiave collaborativa (ad esempio per organizzare il lavoro o per le attività ripetitive) e non decisionale [17]. Ad oggi, lo strumento principale di detection delle immagini pedopornografiche online è ancora PhotoDNA, un semplice software di riconoscimento automatico delle immagini, introdotto da Microsoft nel 2009 [18].
La responsabilità e nondimeno le conseguenze psichiche [19]di questo tipo di attività restano pertanto interamente addossate a questi lavoratori invisibili, che passano le loro giornate a preservare l’utente da tutto ciò di peggio che il web abbia da offrire.
La diffusione incontrollata dei dati personali sui social media
Il moderatore non può che occuparsi dei contenuti evidentemente dannosi, quelli vietati dalle leggi o dalle policy delle sue piattaforme; ma non sempre la dannosità risulta palese o agevolmente accertabile a un primo sguardo, sia pure a quello di un professionista.
Così, è possibile – anzi, frequente – che nelle maglie del filtro passi qualcosa che sembra lecito solo in superficie: non il video di un’esecuzione, non una palese minaccia o hate speech, ma “semplici” dati personali, apparentemente al loro posto nel contesto in cui si trovano ma che nascondono dietro di sé un elevato potenziale lesivo.
Nel considerare tale potenziale, è opportuno, per quanto lapalissiano, specificare come quasi sempre la pubblicazione di un’informazione sul feed di un social network coincida con la sua diffusione.
Nel caso in cui l’original poster abbia utilizzato dei tag (es. hashtag) il contenuto viene indicizzato all’interno del motore di ricerca della piattaforma stessa, mettendolo a disposizione diretta del resto degli utenti, che possono a quel punto ricondividerlo all’interno dello stesso canale o altrove.
Anche in assenza di un tag, il contenuto può essere riproposto dal social agli altri utenti sulla base di valutazioni algoritmiche fondate su vari fattori, interni (si pensi ai metadati di una qualsiasi fotografia, come pure ai parametri risultanti dalla profilazione del nostro comportamento online) od esterni (quali, ad esempio, le altrui preferenze ed interessi).
Privacy e impostazioni di condivisione: limiti e falsa sicurezza
Quanto detto riguarda i post pubblicati su profili pubblici; impostazioni privacy più stringenti riducono, com’è ovvio, le possibilità di diffusione, ma non le azzerano: è sufficiente che uno solo utente della limitata cerchia che ha accesso a un’informazione protetta la ripubblichi senza restrizioni per innescare il processo sopra descritto e vanificare qualunque accorgimento possa aver adottato il primo condivisore.
Nonostante le statistiche sull’utilizzo di internet [20] e una certa narrativa portata avanti sia dai media tradizionali che dai nuovi media [21], si noti, a margine, come le abitudini social degli utenti inizino a mostrare qualche timida inversione di tendenza: da più parti vengono paventati possibili esodi di massa dalle piattaforme social [22], mentre su Facebook ad aumentare sono più che altro i profili di persone decedute [23].
L’engagement passivo
Al contempo, le piattaforme che mantengono rilevanza sembrano essere sempre più focalizzate sull’engagement passivo, con la generalità degli utenti che fruisce di contenuti resi disponibili da una piccola parte degli stessi [24].
Tuttavia, anche l’ipotetico utilizzo dei social come strumenti di fruizione passiva non azzererebbe le problematiche di sovraesposizione individuale. In primo luogo, qualora in tali contenuti siano coinvolti soggetti terzi diversi dai creator [25] non sempre questi ultimi si preoccupano di adottare i necessari accorgimenti per la tutela di immagine, dignità e reputazione dei soggetti coinvolti [26]. E persino immaginando di interrompere radicalmente ogni attività di condivisione, rimarrebbe la problematica dei dati già presenti online.
Se le statistiche della Domus Inc. ci hanno dato un’idea dell’attuale traffico informativo, dobbiamo pur tenere conto del fatto che questi dati si aggiungono, uno strato alla volta, ad un patrimonio storico preesistente, in un ambiente in cui i confini tra passato, presente e futuro sono divenuti meno netti e le informazioni risultano continuamente disponibili ed accessibili, come in una sorta di presente perenne.
Quanti dati sono presenti online? L’analisi di Gareth Mitchell
Il giornalista della BBC Gareth Mitchell, su richiesta dei lettori di BBC Science Focus, prova a formulare un’ipotesi su quanti dati possano essere presenti online nel complesso:
One way to answer this question is to consider the sum total of data held by all the big online storage and service companies like Google, Amazon, Microsoft and Facebook. Estimates are that the big four store at least 1,200 petabytes between them. That is 1.2 million terabytes (one terabyte is 1,000 gigabytes). And that figure excludes other big providers like Dropbox, Barracuda and SugarSync, to say nothing of massive servers in industry and academia[27].
Questa stima, benché approssimativa e molto riduttiva, è abbastanza per dare un’idea del perché il problema della diffusione dei dati, ad oggi, non possa essere risolto semplicemente smettendo di condividere informazioni o cercando di ripulire dai nostri dati gli angoli più visibili di internet.
In ogni caso, al netto dei possibili scenari futuri e delle piccole ondate di defezione dagli sviluppi incerti, i social e la rete internet restano innegabilmente affollati.
Il futuro dei social media
Considerato lo scenario descritto, e a mente delle considerazioni del capitolo 2, è ragionevole domandarsi se effettivamente ogni utente italiano o europeo abbia in concreto la possibilità di esercitare quel diritto al controllo delle proprie informazioni che dovrebbe costituire il nucleo duro e il minimo comun denominatore delle diverse declinazioni di privacy; se possa, quantomeno, decidere se e come essere rappresentato online, cosa condividere e cosa tenere per sé, ed attivare in modo efficace i diritti che gli riconosce il GDPR.
È chiaro che l’effettività di tale diritto – di tale basilare possibilità di controllo – risulta ancor più impellente per alcune categorie di interessati meritevoli di tutele rafforzate, quali ad esempio i minori.
La serie di articoli proseguirà affrontando un tema di grande attualità: l’esposizione dei minori sui social media e il fenomeno dello sharenting. Esamineremo le implicazioni legate alla tutela della privacy e dei diritti dei più giovani nell’era digitale. Per un approfondimento completo, ti invitiamo a scaricare il white paper di Marta Zeroni, “Sovraesposizione e controllo sui dati nell’ecosistema informativo online”.
Note:
[1] RAZ G., ‘Lo’ And Behold: A Communication Revolution (NPR). Ultimo accesso il 27 gennaio 2024.
[2] Lo and Behold: Reveries of the connected world, Werner Herzog, 2016.
[3] LICKLIDER J.C.R., TAYLOR R. W., The Computer as a Communication Device in Science and Technology, 1968, p. 1.
[4] Si pensi al citato caso Esfandiary (supra), affrontato dalla Corte di Cassazione nel 1975, così come alle vicende di Diana Spencer: il Protection from Harassment Act, che sanciva la responsabilità civile e penale dei membri dei comportamenti persecutori di giornalisti, paparazzi e altri membri dei media, fu adottato dal Parlamento inglese solo poche settimane prima della morte di Spencer. Simili normative furono proposte ed adottate negli anni ’90 anche negli USA. Sul punto: CURRY R.J.J., Diana’s Law, Celebrity and the Paparazzi: The Continuing Search for a Solution in Journal of Computer & Information Law, 18, 4, 2000.
[5] ACCORNERO P.G., Cinquant’anni fa le schedature Fiat (La Voce e il Tempo). Ultimo accesso il 27 gennaio 2024.
[6] Si fa riferimento ai concetti di comunicazione e diffusione così come definiti dal vecchio articolo 4 del D.Lgs 196/2003.
[7] Già nel 2008, Arianna Huffington riteneva che, con i dovuti accorgimenti, la rete avrebbe potuto salvare i giornali anziché decretarne la fine: ALTERMAN E., Out of Print (New Yorker). Ultimo accesso il 28 gennaio 2024.
[8] PASCOLETTI M., Il caso di Giovanna Pedretti: da una non notizia alla copertura mediatica di un presunto suicidio (Valigia Blu). Ultimo accesso il 27 gennaio 2024.
[9] Ma si tenga a mente che la demografia della rete è popolata anche da utenti diversi dalle persone fisiche: i social bot.
[10] 4chan è un imageboard conosciuto per essere stato di frequente al centro di polemiche e controversie: MEO T., Due team di linguisti affermano di aver scoperto chi sono i fondatori di QAnon (Wired Italia). Ultimo accesso il 10 febbraio 2024. L’inizio del peggio di Internet (Il Post). Ultimo accesso il 10 febbraio 2024.
[11] È ormai acclarato il ruolo che avrebbero svolto le interazioni su Facebook nell’assalto al Campidoglio di Capitol Hill: TIMBERG C., DWOSKIN E., ALBERGOTTI R., Inside Facebook, Jan. 6 violence fueled anger, regret over missed warning signs (The Washington Post). Ultimo accesso il 28 gennaio 2024; BINDER J.F., KENYON J., Terrorism and the internet: How dangerous is online radicalization? in Frontiers in Psychology, 13, 2022; LORENZ T., The online incel movement is getting more violent and extreme, report says (The Washington Post). Ultimo accesso il 28 gennaio 2024.
[12] PIACENZA D., La correzione del mondo, Einaudi, 2023.
[13] HAN B.C., Infocrazia, Einaudi, 2023, p. 50.
[14] LYMN T., BANCROFT J., The use of algorithms in the content moderation process (GOV.UK). Ultima consultazione in data 31 gennaio 2024.
[15] ZUBOFF S., Il capitalismo della sorveglianza, Luiss University Press, 2018, p. 524.
[16] LYMN T., BANCROFT J., art. cit.
[17] VINCENT G., AI won’t relieve the misery of Facebook’s human moderators (The Verge). Ultima consultazione in data 31 gennaio 2024.
[18] BUNI C., CHEMALY S., The Secret Rules of the Internet (The Verge). Ultima consultazione in data 31 gennaio 2024.
[19] FRANCHI J., Gli obsoleti, Agenzia X, 2021, pp. 236-247.
[20] Internet usage worldwide – Statistics & Facts (Statista). Ultimo accesso il 5 febbraio 2024.
[21] TREEM J.W., DAILEY S.L., BIFFL D., What We Are Talking About When We Talk About Social Media: A Framework for Study in Sociology Compass, 10, 9, 2016.
[22] SANDLE T., Are we heading for a social media exodus? (Digital Journal). Ultimo accesso il 6 febbraio 2024.
[23] SIGNORELLI A.D., Un esercito di morti sta marciando su Facebook (Wired Italia). Ultimo accesso il 5 febbraio 2024.
[24] SIGNORELLI A.D., La fine dei social network? (Spotify). Ultimo accesso il 5 febbraio 2024; BARBERA D., 12 milioni di persone hanno seguito il concerto virtuale di Travis Scott su Fortnite (Wired Italia). Ultimo accesso il 9 febbraio 2024; Marrageddon è stato lo show musicale più visto su Twitch in Europa nel 2023 (Rebel Mag. Ultimo accesso il 9 febbraio 2024.
[25] Si fa riferimento, ad esempio, alle street interview e ai video-prank.
[26] STEFANELLO V., Il problema dei tiktoker che riprendono i passanti senza il loro consenso (Il Post). Ultimo accesso il 5 febbraio 2024.
[27] MITCHELL G., How much data is on the internet? (BBC Science Focus). Ultimo accesso il 9 febbraio 2024.

Consulente Privacy e IT Law, auditor, Data Protection Officer e formatrice in materia di protezione dei dati personali e società digitale. Laureata magistrale in giurisprudenza all'Università degli Studi di Padova, con perfezionamento in criminalità informatica e investigazioni digitali alla Statale di Milano e master di secondo livello in Informatica Giuridica presso La Sapienza di Roma.





