

L’analisi dei rischi. Un approccio con la logica Fuzzy
Il rischio è il risultato finale, diretto, indiretto o consequenziale ad un’azione volontaria, involontaria o ad un evento accidentale ed è determinato di norma come il prodotto fra la probabilità che un evento pericoloso si realizzi e l’impatto (danno) da questo provocato.
Le aziende devono svolgere una attività continua di analisi del rischio in diversi ambiti:
- rischi operativi (quali perdita di beni di qualunque tipo, siano essi tangibili o intangibili…);
- rischi di conformità (derivanti dalla violazione di normative…);
- rischi legali (quali cause con le controparti, quali clienti, fornitori, dipendenti…);
- rischi reputazionali (derivanti da eventi che possono ledere l’immagine dell’organizzazione…).
o come prevede il GDPR:
- il rischio per i diritti e le libertà delle persone fisiche
Le varie categorie di rischio non sono fra loro distinte ed autonome.
La violazione di una normativa, ad esempio, può comportare sia una sanzione (e relativa perdita economica), sia un impatto sulla reputazione dell’azienda.
Inoltre, se la sanzione ha conseguenze operative (ad esempio il blocco dei trattamenti di dati personali e la conseguente impossibilità di erogare un servizio) può portare anche a cause con la clientela per mancato rispetto dei contratti di fornitura.
Si creano così catene di relazioni che rendono difficile valutare con precisione il reale impatto di un evento. Questa valutazione può avvenire infatti a diversi livelli e con diversi gradi di complessità.
È possibile ridurre il rischio intervenendo su impatto e probabilità, adottando adeguate contromisure che possono ridurre uno o entrambi i fattori.
L’implementazione di contromisure ha ovviamente un costo, che deve essere vantaggioso, rispetto alla riduzione del rischio derivante dalla loro implementazione.
Per tale motivo si effettua in genere un’analisi del rischio prima (Rischio inerente) e dopo l’implementazione delle contromisure (Rischio residuo).
In questo modo è possibile valutarne quale potrebbe essere l’efficacia.
La valutazione di dove sia più conveniente intervenire e quali contromisure adottare è uno degli aspetti più importanti che consegue ad una corretta analisi dei rischi.
Esistono anche altre modalità per affrontare un rischio (oltre che gestirlo) quali:
- evitarlo non mettendo in atto le azioni che possono determinarlo;
- trasferirlo a soggetti che istituzionalmente si occupano di gestirlo, come le assicurazioni o tramite opportune clausole contrattuali;
- accettarlo, non mettendo in atto alcuna azione.
È comunque importante notare che il soggetto che effettua l’analisi del rischio non è necessariamente il soggetto che è esposto al rischio stesso.
È il caso sopracitato della valutazione dei rischi del GDPR, dove il rischio valutato non è quello dell’azienda o dei sui asset, ma dei soggetti interessati di cui l’azienda tratta i dati.
Comprendere questo aspetto è fondamentale in quanto si tratta quindi di un rischio non disponibile, che l’azienda dovrebbe in ogni caso ridurre assolutamente al minimo.
Da lì la necessità, nei casi di rischio elevato, di condurre una PIA.
Per condurre un’analisi dei rischi esistono numerosissimi strumenti e relative catalogazioni.
Fra le consigliate quella di ISCOM e quella di ENISA:
http://www.isticom.it/index.php/archivio-pubblicazioni/3-articoli/111-news-pub9
Tab. 1 – Tipologie di analisi dei rischi secondo la Linea guida ISCOM – Risk analisys approfondimenti
| Qualitativo | valutazione del rischio su una scala qualitativa (ad esempio alto, medio, basso). |
| Quantitativo
|
riconduce le valutazioni ad un valore numerico puntuale, spesso inteso come la perdita economica derivante dal verificarsi del rischio. Si tratta di un approccio più difficile ed oneroso del primo perché costringe ad un censimento ed una valorizzazione degli asset e ad una valorizzazione delle perdite che si avrebbero in caso di incidente. |
| Semi-quantitativo | compromesso fra i primi due, nel quale le valutazioni sono effettuate in termini qualitativi e, successivamente, trasformate in numeri per poterle elaborare attraverso algoritmi di calcolo, come se si trattasse di valutazioni quantitative… |
Se rappresentiamo l’IMPATTO con una serie di valori che vanno da Trascurabile a Grave, una possibile rappresentazione utilizzando la logica fuzzy è quella rappresentata nella Fig. 1
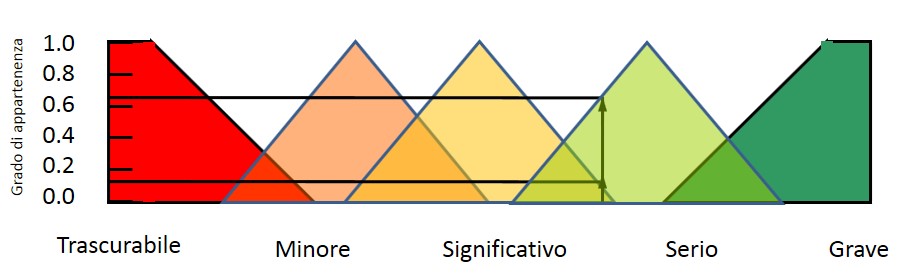
Come applicare queste possibilità all’analisi dei rischi?
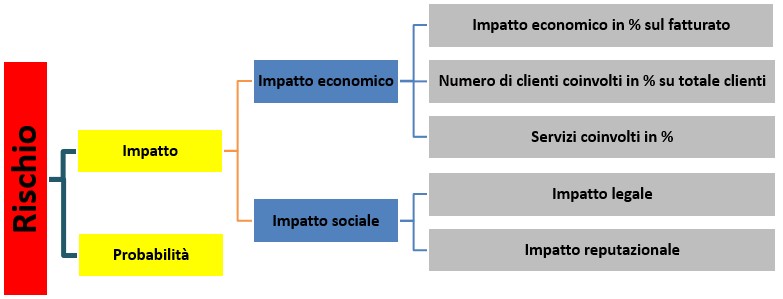
Sviluppiamo un esempio di Sistema Esperto per l’analisi dei rischi partendo da una definizione di RISCHIO basata su 5 valori qualitativi che vanno da VeryLight a VeryHigh, derivanti dalla combinazione di 5 valori di IMPATTO (Fig. 2) che vanno da Insignificant a Severe e 5 valori di PROBABILITà (Fig. 3) che vanno da Rare a Very Likely.
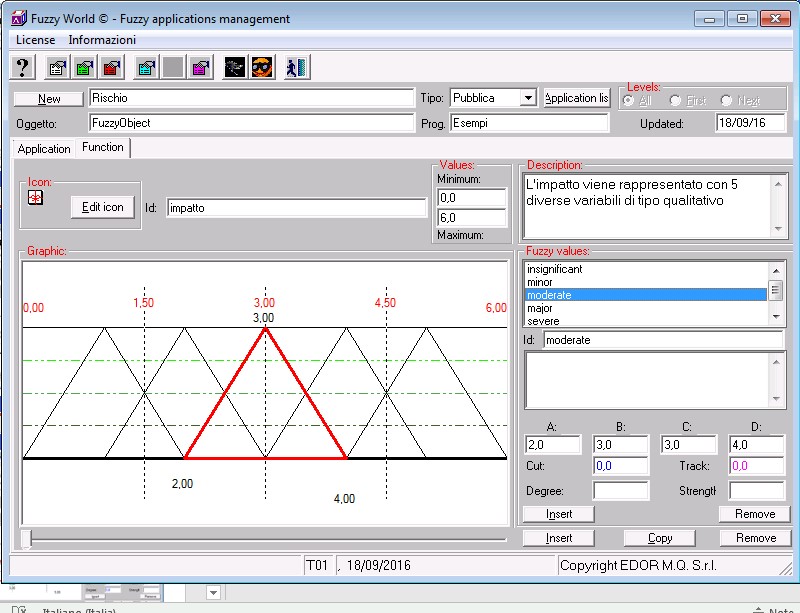
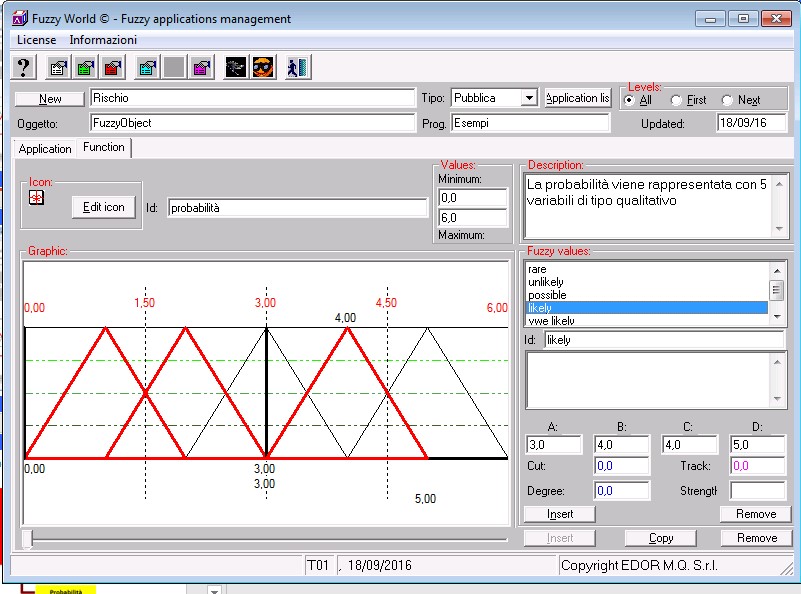
In termini di regole, la logica applicabile per la determinazione del RISCHIO è la seguente:
IF PROBABILITÀ IS xx AND IMPATTO IS xx THEN RISCHIO IS xx
Per ragioni tecniche, conviene suddividere il nostro Sistema esperto in piccole parti (“chip di conoscenza”) che modellizzano il sistema in esame.
Nella figura seguente viene presentato un primo chip di conoscenza, composto da 2 antecedenti (informazioni note) ed un conseguente (risultato dell’applicazione delle regole agli antecedenti).
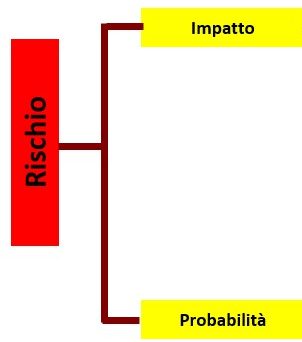
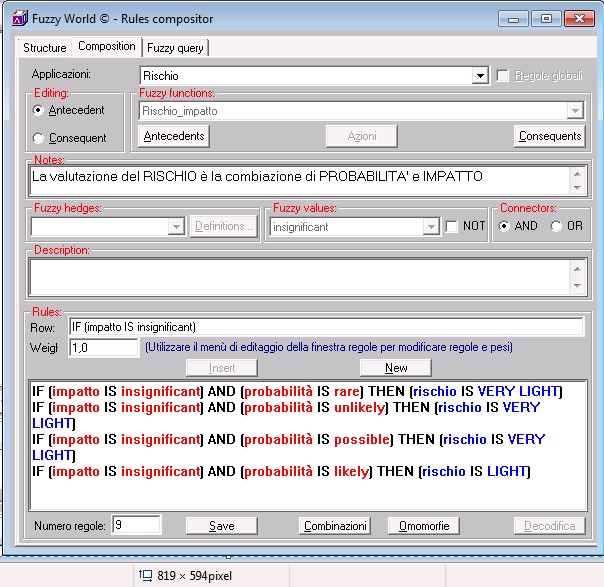
Fino a qui nulla di particolare, ma iniziamo ora dare delle regole più articolate per definire l’IMPATTO, dandone una valutazione in funzione ad esempio del numero di servizi o dal numero di clienti impattati o dalle possibili conseguenze legali o reputazione:
Analogamente, per quanto attiene alla PROBABILITÀ possiamo considerare ad esempio il numero di avvenimenti nel corso dell’anno per definire se un evento è raro o molto frequente.
Ne risulta il seguente modello:
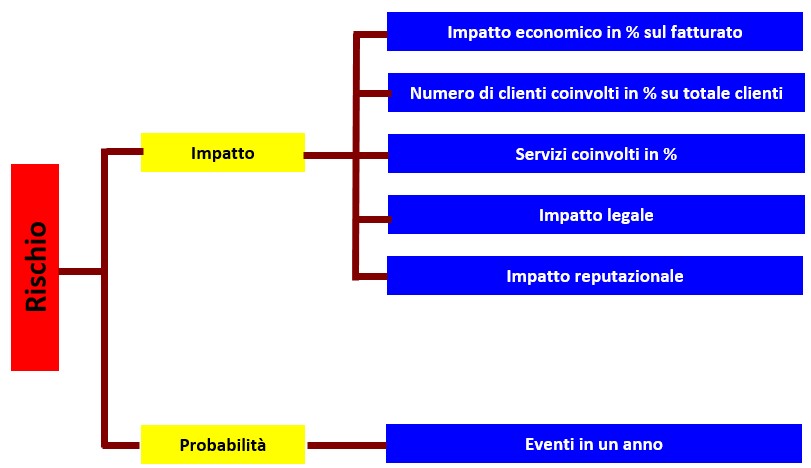
Nell’esempio le variabili economiche usano una scala di 10 valori in progressione (Fig. 7).
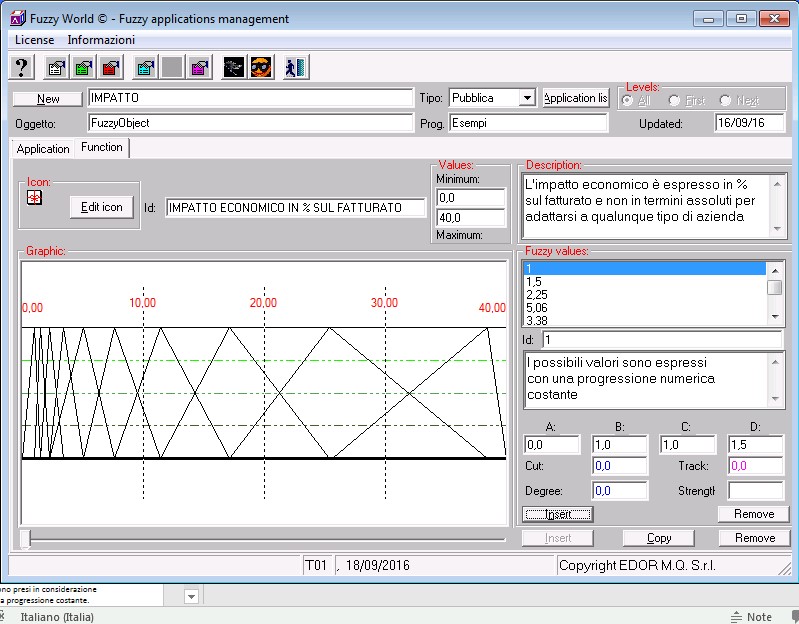
Le possibili combinazioni di tutte le variabili così introdotte avvengono mediante una regola di questo tipo:
IF impatto economico in % sul fatturato IS x
AND impatto economico in % sul fatturato IS <=x+1
AND n. di clienti coinvolti in % su totale clienti IS y
AND n. di clienti coinvolti in % su totale clienti IS <=y+1
…
AND impatto legale IS si/no
AND impatto reputazionale IS si/no
THEN impatto IS n
Se volessimo elencarle tutte, avremmo un numero rilevantissimo di possibili combinazioni per le quali il risultato (n) deve essere attribuito manualmente dall’esperto.
Fortunatamente questo non è necessario in quanto è possibile addestrare la rete neurale mediante la compilazione di fogli Excel sui quali rappresentare i valori di antecedenti e conseguenti (Fig. 8).
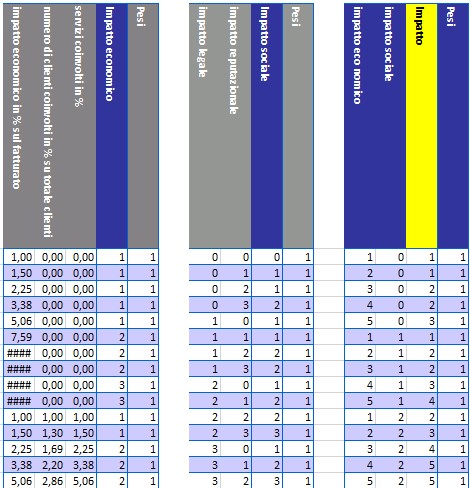
Questa modalità operativa presenta enormi vantaggi; il primo è che non è necessario formulare una riga di antecedenti e conseguenti per ogni possibile combinazione di valori. Sarà infatti la rete neurale che determinerà il modo di comportarsi nelle varie situazioni analogamente a quello che fa un bambino che, imparando a camminare, non sperimenta tutte le possibili combinazioni che possono presentarsi nella realtà. La rete neurale elaborerà tutte le possibili soluzioni; eventuali ulteriori regole potranno inoltre essere aggiunte dinamicamente durante l’utilizzo dell’applicazione.
Un vincolo di questo modello è che funziona con un numero limitato di antecedenti (2 o 3) per ogni conseguente. È quindi necessario intervenire ancora una volta sul nostro modello di analisi dei rischi:
A cura di: Lorenzo Schiavina e Giancarlo Butti

Lorenzo Schiavina, professore di Ricerca Operativa all'Università Cattolica, si occupa di informatica dal 1964. Autore di oltre 80 pubblicazioni è stato il primo in Italia ad occuparsi di programmazione ad oggetti (Smalltalk). Ha sviluppato applicazioni in ambito finanziario e gestionale, fra i quali MIDA (pacchetto ufficiale di Hewlett-Packard per 5 anni) di cui sono stati venduti in Italia più di 250.000 esemplari. Si occupa da 30 anni di logica fuzzy e nel 2000 ha sviluppato FuzzyWorld ambiente per lo sviluppo di SE per la didattica ed applicazioni reali.

Internal Auditor, Consulente Privacy e Cyber Security





