

Quando l’AI non è una bacchetta magica: promesse e limiti dell’intelligenza artificiale nella cybersecurity
Al Forum ICT Security 2025, il professor Marco Mellia del Politecnico di Torino ha sfatato alcuni miti sull’AI applicata alla sicurezza informatica, illustrando però le reali potenzialità degli agenti autonomi
Nel contesto della 23a edizione del Forum ICT Security, tenutosi a Roma il 19 e 20 novembre 2025, l’intervento “AI, LLM, Agentic AI e Cyber Security: Potenzialità e limiti” del professor Marco Mellia ha rappresentato uno dei momenti più illuminanti dell’evento. Docente ordinario presso il Dipartimento di Automatica e Informatica del Politecnico di Torino e co-fondatore di Ermes Cyber Security, il relatore ha affrontato con rigore scientifico e schiettezza divulgativa uno dei temi più dibattuti del momento: quanto c’è di reale dietro la “bacchetta magica” dell’intelligenza artificiale applicata alla cybersecurity?
L’intervento si è articolato in due parti distinte. La prima, che l’esperto ha eloquentemente definito “il pericolo dello zucchero”, ha preso di mira le promesse mirabolanti di alcuni sistemi AI che sostengono di poter classificare il traffico di rete cifrato. La seconda parte ha invece esplorato un territorio più promettente: quello degli agenti AI autonomi applicati all’analisi forense.
Prima parte: lo zucchero che nasconde l’amaro
Il punto di partenza dell’analisi è stato un fenomeno che chi lavora sulla frontiera della ricerca osserva con crescente perplessità: l’emergere di soluzioni commerciali e paper accademici che promettono di “vedere” all’interno delle comunicazioni cifrate grazie all’intelligenza artificiale. Come ha osservato ironicamente lo speaker, “arriva l’AI e ti permette di risolvere problemi che fino a ieri erano impossibili, per esempio classificare il traffico cifrato”. Un’affermazione che, a prima vista, sa di bacchetta magica.

L’approccio utilizzato da questi sistemi è mutuato dal successo ottenuto in altri settori, in particolare dal Natural Language Processing. L’esperto ha citato BERT, il modello sviluppato da Google per la traduzione automatica, come esempio paradigmatico di representation learning: si allena una rete neurale a “leggere” enormi quantità di testo, creando una rappresentazione interna che può poi essere riutilizzata per compiti specifici come traduzioni o correzioni.
Il ragionamento dei ricercatori è stato apparentemente lineare: “Se una macchina di questo tipo è in grado di imparare tutte le lingue, vuoi che non sia in grado di imparare anche i pacchetti di rete?” È nato così l’approccio del masked auto-encoder applicato al traffico Internet: si nasconde parte di un pacchetto e si allena il modello a ricostruire la parte mancante. Una volta ottenuta questa rappresentazione, la si dovrebbe poter usare per classificare il traffico.
Risultati troppo dolci per essere veri
I risultati pubblicati sono effettivamente impressionanti. Il relatore ha mostrato come lavori apparsi alle più prestigiose conferenze del settore — KDD, The Web Conference, AAAI, IEEE S&P — riportino accuratezze del 95-98% nel classificare traffico cifrato proveniente da 120 siti web diversi. “Fa venire un po’ i brividi”, ha commentato, “perché se tutto è cifrato, come diavolo fai a dirmi se quello che c’è dentro è di Facebook o del Corriere?”
Ed è qui che entra in gioco lo scetticismo del ricercatore. Il docente torinese ha invitato la platea a ricordare tre nomi: Rivest, Shamir e Adleman — i padri dell’algoritmo RSA che rende possibili le transazioni bancarie sicure su Internet. “Se noi ci fidiamo di loro”, ha argomentato, “quello che ci hanno detto gli altri non potrebbe funzionare.”

Le insidie metodologiche
L’analisi critica ha rivelato tre insidie fondamentali nei lavori esaminati. La prima è di natura concettuale: il processo di masked auto-encoding presuppone di poter ricostruire una sequenza a partire da un’altra. Ma con il traffico cifrato si lavora con sequenze casuali: “Come fai da una sequenza casuale a ricostruire un’altra sequenza casuale? La giusta sequenza casuale non è possibile. Checché ne dica chi gioca al lotto.”
La seconda insidia riguarda la metodologia sperimentale. Chi lavora con il machine learning sa che bisogna separare rigorosamente i dati di training da quelli di test. Ma lo speaker ha scoperto che molti lavori hanno commesso un errore cruciale: hanno inserito lo stesso flusso di dati sia nel training che nel test set. Il risultato è che i modelli hanno imparato degli shortcut — scorciatoie che non rappresentano realmente il problema. “Il machine learning è bravissimo a trovare scorciatoie”, ha spiegato con una metafora efficace: “Se vedo 100 foto di uomini con gli occhiali e 100 foto di donne senza occhiali, il modello guarda agli occhiali, non gliene frega niente del resto della foto.”
Correggendo questo errore metodologico — assicurandosi che ogni flusso finisse interamente o nel training o nel test — le prestazioni sono crollate: “meno del 50% di accuratezza”. Come ha ricordato citando Shakespeare: “Not everything that glitters is gold” — non tutto ciò che luccica è oro.
La terza insidia è ancora più rivelatrice. Se il representation learning funzionasse davvero, non dovrebbe essere necessario ri-allenare l’intera rete: basterebbe “congelare” l’encoder e allenare solo la testa di classificazione. Ma bloccando l’encoder, “non funziona più niente”. Tradotto: quei modelli non hanno realmente imparato a rappresentare il traffico di rete. “E per fortuna”, ha concluso il relatore, “RSA ancora hanno ragione.”
Seconda parte: gli agenti AI, una rivoluzione più concreta
Sgombrato il campo dalle false promesse, l’intervento si è spostato su un territorio più promettente. “Quanti di voi usano ChatGPT?”, ha chiesto il relatore alla platea. La risposta, prevedibilmente, è stata un mare di mani alzate. Questo uso quotidiano dei Large Language Models come “consulenti” rappresenta il punto di partenza per comprendere il potenziale degli agenti AI.
Attualmente, quando abbiamo un problema di sicurezza — ad esempio con Log4j — consultiamo ChatGPT che ci fornisce suggerimenti. Siamo noi umani ad osservare l’ambiente (i log, il traffico di rete), a formulare la domanda, e poi ad agire sulla base della risposta. Ma cosa succederebbe se sostituissimo l’essere umano in questo ciclo con un pezzo di software?
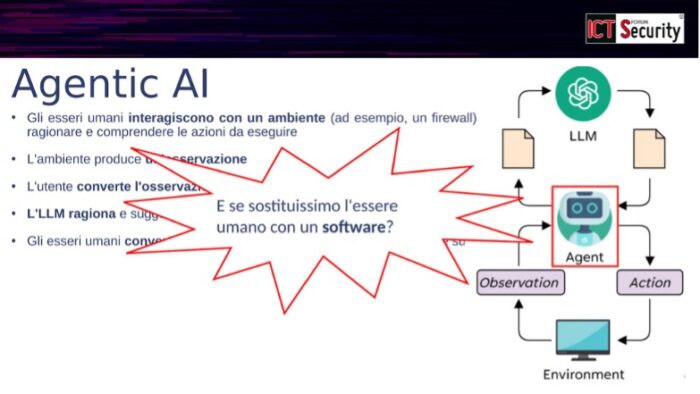
Un agente AI è esattamente questo: un software che interagisce autonomamente con l’LLM, osserva l’ambiente attraverso strumenti dedicati (accesso ai log, analisi dei pacchetti, ricerche web), e può agire direttamente sull’ambiente stesso — configurando sistemi, eseguendo comandi. “Osserva, pensa, cambia, riprova, sbaglia e va avanti”, ha sintetizzato l’esperto.
Un banco di prova rigoroso
Per valutare le reali capacità di questi agenti, il team del Politecnico di Torino ha costruito un ambiente controllato con una ventina di casi di studio. Hanno preso servizi reali — CouchDB, Jenkins, Cacti, SaltStack, GitLab, Apache — in versioni vulnerabili e non vulnerabili, li hanno attaccati con exploit noti, e hanno raccolto log e tracce di rete. Per ogni caso conoscevano esattamente cosa stava succedendo, quale vulnerabilità (CVE) era stata sfruttata, e se l’attacco aveva avuto successo.
All’agente veniva quindi chiesto di analizzare le tracce e rispondere a quattro domande: che sistema sta guardando? Era vulnerabile o no? L’attaccante ha avuto successo? E soprattutto, quale specifica vulnerabilità è stata sfruttata?
Dal fallimento al successo: l’importanza dell’architettura
I primi risultati sono stati deludenti: solo il 14% di precisione nell’identificazione del servizio. L’agente aveva problemi con la gestione della memoria e del contesto, si perdeva durante il ragionamento, e cominciava ad “allucinare” — ad esempio sostenendo che un sistema Cacti avesse problemi di SSH.

Ma lavorando sull’architettura dell’agente, i risultati sono migliorati drasticamente, raggiungendo l’80-90% di precisione nell’identificazione delle CVE. La chiave? Un approccio sequenziale: prima l’agente esamina il traffico e produce un riepilogo, poi controlla tutti i dati e ragiona integrando ricerche web. L’intuizione, ha spiegato il relatore, è stata “evitare il divide et impera“: questi LLM possono processare molti dati, ma non riescono a mantenere il contesto se il problema viene frammentato troppo.
Il confronto tra diversi modelli — DeepSeek R1 e OpenAI o3 — ha mostrato prestazioni sostanzialmente equivalenti. E il costo? “Un paio di dollari per risolvere tutti i casi”, ha rivelato il docente, rendendo la tecnologia accessibile.
La qualità dei report prodotti è stata valutata da una quarantina di esperti del settore, che hanno assegnato punteggi elevati per completezza (4 su 5), utilità (4+) e coerenza logica (4+).
Take home message: opportunità concrete, cautele necessarie
Le conclusioni dell’intervento sono state equilibrate ma nette. L’AI sta rivoluzionando il mondo della cybersecurity? “Assolutamente sì”. Gli agenti AI sono promettenti? “Assolutamente sì”. Ma — e qui sta il punto cruciale — “not everything that glitters is gold“: i sistemi AI faticano a generalizzare e sono invece “bravissimi a prendere scorciatoie”.

Il fatto di poter avere un agente che svolge compiti complessi con l’80-90% di correttezza è, secondo il relatore, “molto più preoccupante — o utile — che andare a guardare dentro i pacchetti”. Ma resta fondamentale non fidarsi ciecamente e chiedersi sempre come e perché un sistema funziona.
In quest’ottica, l’Explainable AI — la capacità di spiegare le decisioni dei modelli — diventa uno strumento essenziale, soprattutto in un campo critico come la cybersecurity. Perché la vera domanda non è se l’AI abbia dato la risposta giusta, ma se l’abbia data per le ragioni giuste — e non perché, metaforicamente, “gli uomini portavano gli occhiali e le donne no”.
L’invito finale è stato quello di sfruttare gli strumenti a disposizione — inclusa la conoscenza umana — senza cedere alle sirene del marketing che promette soluzioni miracolose. Come ai tempi della green energy, quando si arrivò a vendere “il cavo di rete verde che consumava meno”, anche oggi occorre distinguere tra innovazione reale e polvere negli occhi.
Guarda l’intervento completo:

Marco Mellia è professore ordinario al Politecnico di Torino, Italia, dove coordina il centro SmartData@PoliTO su Big Data, Machine Learning e Data Science.
Nel 2002 ha visitato gli Sprint Advanced Technology Laboratories a Burlingame, CA, lavorando all'IP Monitoring Project (IPMON). Nel 2011, 2012 e 2013 ha collaborato con Narus Inc. a Sunnyvale, California, lavorando sul monitoraggio del traffico e sulla progettazione di sistemi di sicurezza informatica. Nel 2015 e nel 2016 ha visitato Cisco Systems a San Jose, California, lavorando su piattaforme di monitoraggio cloud.
I suoi interessi di ricerca riguardano le aree del monitoraggio di Internet, della sicurezza informatica e dell'analisi basata sull'intelligenza artificiale applicata a diverse aree. Marco Mellia è Fellow di IEEE e co-fondatore di Ermes Cyber Security, una start-up che offre soluzioni basate sull'intelligenza artificiale per la protezione web.
Marco Mellia è coautore di oltre 250 articoli pubblicati su riviste internazionali e presentati in importanti conferenze, tutti nell'area delle reti di comunicazione.
Ha vinto il premio IRTF ANR all'IETF-88 e i premi per il miglior articolo a diverse conferenze. è titolare di 15 patent internazionali e ha coordinato diversi progetti di ricerca finanziati dalla Comunità Europea su temi di monitoraggio di Internet e privacy.





