Dentro la mente delle macchine: la nuova frontiera dell’interpretabilità nell’intelligenza artificiale
L’intervento “Decifrare la scatola nera: dall’opacità alla sicurezza” di Simone Scardapane, Professore Associato alla Sapienza Università di Roma, al 23° Forum ICT Security
Lo sviluppo dell’intelligenza artificiale ha rivoluzionato il nostro modo di interagire con essa: oggi possiamo dialogare in linguaggio naturale con modelli generalisti come GPT o Claude, senza possedere competenze avanzate in programmazione o raccolta dati. Questa democratizzazione dell’accesso, però, convive con una forte opacità: i modelli restano spesso “scatole nere”, difficili da comprendere e da controllare, soprattutto quando generano errori o comportamenti inattesi, esponendo l’utente a numerose problematiche. È proprio da questa tensione che ha preso le mosse l’intervento di Simone Scardapane, Professore Associato alla Sapienza Università di Roma, presentato durante il Forum ICT Security 2025 con il titolo “Decifrare la scatola nera: dall’opacità alla sicurezza”.
Al centro della riflessione, il concetto di mechanistic interpretability: lo studio delle strutture interne dei modelli per ricostruire i principi di funzionamento delle loro componenti. Un approccio che permette di individuare i “meccanismi interni” nascosti che generano le risposte, aprendo nuove strade per rendere questi sistemi più sicuri e controllabili.
Il paradosso dei modelli AI: capacità sovrumane ed errori banali
Negli ultimi tre o quattro anni, i Large Language Model hanno seguito una traiettoria di crescita impressionante, sia dal punto di vista computazionale sia per quanto riguarda la quantità di dati utilizzati nell’addestramento. Un aspetto particolarmente interessante di questa evoluzione riguarda le cosiddette emerging properties: man mano che i modelli diventano più grandi e vengono allenati su più dati, si “sbloccano” capacità che prima erano completamente assenti. Come è emerso dall’intervento, «ci sono benchmark in cui funzionano malissimo e poi, superato un certo livello di complessità, funzionano molto bene», fino a raggiungere prestazioni quasi sovrumane in diversi ambiti, dal ragionamento matematico all’analisi di immagini.
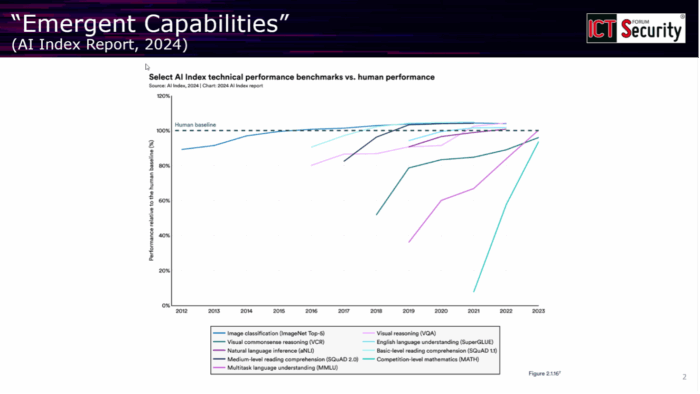
Questa dinamica genera però situazioni paradossali. Benchmark che solo un anno fa sembravano impossibili vengono oggi superati con relativa facilità dai modelli più recenti. Al contempo, gli stessi sistemi capaci di risolvere problemi complessi possono incappare in errori apparentemente banali: il professore ha citato l’esempio di un benchmark del 2025 realizzato da ricercatori dell’Università di Edimburgo, in cui i modelli venivano testati sulla capacità di leggere date e orari da orologi analogici, con risultati sorprendentemente scarsi.
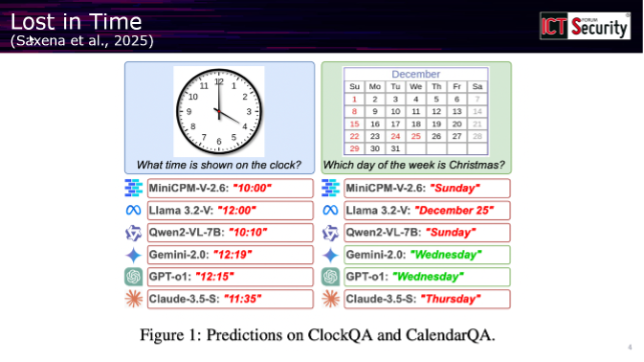
«È abbastanza buffo per chi non conosce questi modelli vedere questa contrapposizione», ha commentato il relatore, «perché ci sono questi modelli che sono quasi sovraumani sotto certi punti di vista e poi fanno degli errori completamente idioti». È proprio questa incongruenza a rendere urgente la necessità di comprendere cosa accade all’interno di questi sistemi.
Due problemi, due sfide
Da questa osservazione emergono due questioni fondamentali. La prima è di natura prettamente scientifica: come quantificare l’explainability? Come entrare effettivamente nella scatola nera per comprendere perché un modello eccelle in alcuni compiti e fallisce in altri? La seconda sfida riguarda invece la comunicazione verso gli utenti finali: una volta ottenuta questa comprensione, come renderla accessibile a chi utilizza quotidianamente questi strumenti?
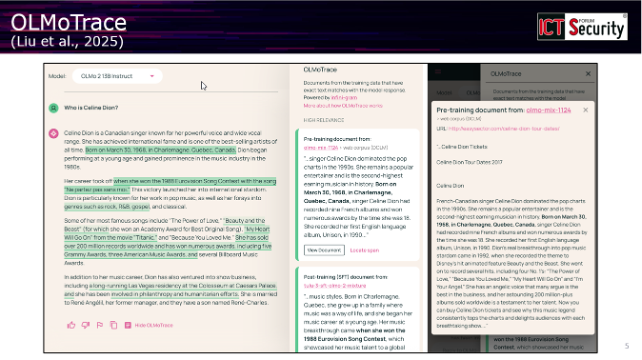
L’intervento ha presentato come esempio OLMo Trace, un’interfaccia sviluppata quest’anno che permette agli utenti di evidenziare parti specifiche di una risposta generata da un modello e visualizzare quali elementi dei dati di addestramento hanno contribuito a quella particolare formulazione. «Se il modello fa un’allucinazione abbastanza strana o una risposta particolarmente strana, l’utente in maniera molto semplice può capire se questo deriva dai dati da cui eravamo partiti», ha spiegato il docente.
Ma la vera sfida va oltre la semplice spiegazione: «Non ci interessa solo spiegare questi modelli, ma ci interessa — e questo è molto più difficile — controllarli». Non si tratta semplicemente di capire perché un modello non funziona, ma di avere «un modo preciso e chirurgico di intervenire sul comportamento di questo modello per farlo funzionare». In alcuni ambiti della computer science questo viene chiamato recourse: la possibilità di utilizzare l’informazione della spiegazione per intervenire sul modello stesso.
Dall’explainability classica alla mechanistic interpretability
Il termine explainability nell’ambito dell’intelligenza artificiale ha una storia complessa. Il relatore ha ripercorso l’evoluzione di questo campo, partendo da quello che oggi viene definito approccio “classico”, sviluppatosi circa dieci-quindici anni fa con la popolarizzazione delle reti neurali, prima dell’avvento dei Large Language Model.
L’explainability classica si concentrava principalmente sull’evidenziare quali parti dell’input fossero maggiormente rilevanti per una determinata predizione: nell’ambito della classificazione di immagini, ad esempio, si cercava di visualizzare su quali aree dell’immagine il modello si stesse concentrando. Tuttavia, questo approccio ha mostrato limiti significativi. «Quello che ci si accorge è che è veramente difficile da un lato dare questa informazione agli utenti, dall’altro farci qualcosa con questa informazione», ha osservato il professore.

Il problema principale era che questo tipo di explainability era stata «venduta tantissimo» nel periodo 2018-2019, con molti che proponevano soluzioni “explainable” come alternativa all’AI black box. «C’è stato un periodo in cui ci si è resi conto che per questo tipo di cose non funziona tanto bene»: i metodi si sono rivelati poco robusti, “brittle” nel gergo tecnico, e soprattutto non permettevano di intervenire effettivamente sul comportamento del modello.
La svolta è arrivata intorno al 2021, quando un gruppo di ricercatori — oggi distribuiti tra Anthropic, Google e OpenAI — ha pubblicato quello che il docente definisce un “manifesto” per proporre un nuovo paradigma: la mechanistic interpretability. L’obiettivo di questo approccio è trovare all’interno degli enormi modelli, costituiti da miliardi di parametri e rappresentazioni, quelli che vengono chiamati “circuiti” o “meccanismi interpretabili”. Il paragone, per quanto imperfetto, è con il lavoro dei neurologi che cercano meccanismi funzionali nei neuroni o nelle aree del cervello.
Dentro la scatola nera: i circuiti nascosti
Uno dei risultati più significativi emersi da questo nuovo approccio è la scoperta delle cosiddette induction heads, circuiti interni alle reti neurali che si occupano di copiare informazioni dal prompt da un punto all’altro della sequenza. Il relatore ha illustrato il meccanismo con un esempio tratto da un testo letterario: se il modello incontra “Miss Dursley” all’inizio di un testo, l’induction head è quel meccanismo che, quando il modello legge successivamente “Miss”, lo porta a completare con “Dursley” recuperando l’informazione precedente. «È un meccanismo di induzione abbastanza semplice», ha commentato, «però era molto sorprendente, molto interessante che si fosse in grado di trovare questi componenti dentro la rete neurale».
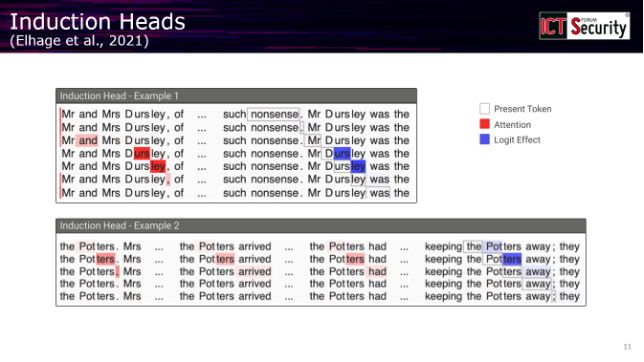
La ricerca ha ricevuto un’accelerazione significativa quando si è riusciti ad automatizzare questo tipo di analisi. L’intervento ha fatto riferimento a uno dei contributi più importanti del campo, un blog post pubblicato da Anthropic in cui i ricercatori hanno dimostrato di essere in grado di identificare automaticamente miliardi di componenti interpretabili all’interno dei loro modelli. «Vi invito fortemente ad andare a cercare questo articolo e a leggerlo perché ci sono tantissimi esempi di queste componenti e sono tutti estremamente interessanti», ha suggerito il professore.

Tra gli esempi più noti c’è il cosiddetto “Golden Gate neuron”, un’unità che si attiva ogni volta che viene menzionato, visto o discusso il Golden Gate Bridge. Ma i ricercatori hanno identificato anche componenti che si attivano quando il modello risponde in modo eccessivamente adulatorio (sycophantic, nel gergo tecnico), quando genera contenuti potenzialmente non sicuri, o quando utilizza capacità di ragionamento matematico.
Un’applicazione particolarmente promettente riguarda i modelli scientifici sviluppati per biologia, medicina e chimica. In questi contesti, l’analisi dei meccanismi interni ha rivelato circuiti che si attivano su parti specifiche del DNA relative a determinate proteine, mostrando «un match molto forte tra quello che lo scienziato, il biologo, il chimico si aspetterebbe dentro questi modelli e quello che effettivamente ci troviamo».
Steering: il controllo chirurgico del comportamento
La domanda fondamentale che emerge da queste ricerche è: possiamo utilizzare questa conoscenza per controllare effettivamente il comportamento dei modelli? La risposta, secondo le evidenze più recenti, sembra essere positiva. Il termine tecnico per questa capacità di intervento è steering.
Il relatore ha illustrato come le unità interpretabili identificate all’interno dei modelli possano essere manipolate direttamente: «Fondamentalmente questi sono unità interne della rete neurale su cui noi possiamo intervenire. Possiamo metterle a zero, possiamo moltiplicarle, possiamo utilizzarle come direzione nello spazio delle attivazioni». Un’applicazione concreta di questo principio sono i cosiddetti persona vectors, direzioni nello spazio dei parametri che funzionano come «bottoni che potete attivare» e che «cambiano completamente la personalità del modello», rendendolo più sicuro, più gentile, più preciso o modificandone altre caratteristiche comportamentali.
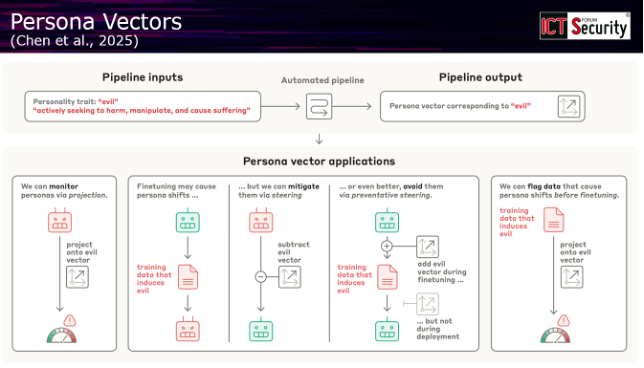
Le implicazioni per la sicurezza sono immediate: «Se immaginate di trovare l’unità specifica che si attiva quando il modello vi sta parlando di come fare un particolare attacco informatico, se la spegnete idealmente dovreste essere in grado di togliere questa capacità al modello e quindi renderlo più safe». Questo, ha sottolineato il docente, «è il grosso motivo per cui stanno studiando questi modelli».
Un esempio illuminante riguarda un errore che qualche anno fa era diventato virale sui social network: alcuni modelli affermavano che 9.11 fosse maggiore di 9.8. Analizzando le unità che si attivavano durante questa risposta errata, i ricercatori hanno scoperto che entravano in gioco meccanismi legati all’attacco dell’11 settembre, a versetti della Bibbia e ad altri concetti completamente irrilevanti per una semplice comparazione numerica. «Queste sono ovviamente unità che non hanno nessuna rilevanza alla domanda specifica», ha osservato il professore. Disattivando chirurgicamente questi meccanismi e rigenerando la risposta, il modello forniva la risposta corretta.
Verso nuove interfacce: il Circuit Tracing
Il livello più avanzato di questa tecnologia è rappresentato dal Circuit Tracing, un meccanismo automatico che fornisce una rappresentazione circuitale simbolica dei vari meccanismi attivati durante una generazione e di come si interconnettono tra loro per produrre la risposta finale.
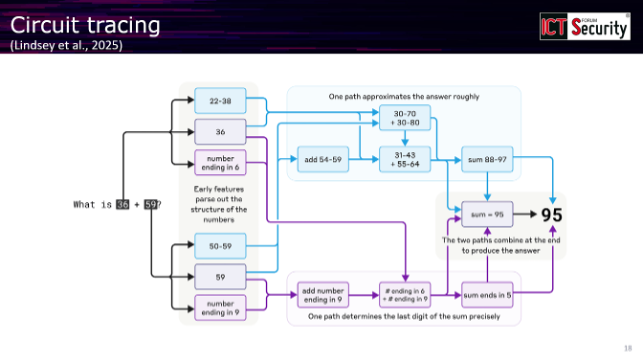
«A sinistra avete la domanda, a destra avete la risposta. In mezzo ci sarebbe una black box che è il modello», ha spiegato il relatore. «Se avete accesso a questo tipo di tracing, fondamentalmente potete veramente andare lì, cliccarci e dire: no, questa specifica connessione tra i due meccanismi non mi sembra corretta, disattivala». Rigenerando la risposta, questa cambierà in funzione dell’intervento effettuato.
I risultati sono promettenti anche sul versante delle prestazioni: si è osservato che aumentando l’attivazione di meccanismi specifici legati al ragionamento matematico, i modelli migliorano su determinati benchmark senza alcun altro intervento. Applicazioni analoghe stanno emergendo anche nell’ambito della generazione di immagini, dove è possibile controllare quali meccanismi attivare in specifiche aree dell’output.
Conclusioni e prospettive
Il quadro delineato dall’intervento mostra un campo di ricerca in rapida evoluzione, ancora poco discusso nel dibattito pubblico ma oggetto di investimenti significativi da parte dei principali laboratori di intelligenza artificiale. «Ci sono grossi investimenti, soprattutto da OpenAI, DeepMind, Anthropic e altre startup più piccole negli Stati Uniti», ha osservato il relatore, sottolineando come questa ricerca «possa cambiare in maniera significativa quelle che saranno le interfacce avanzate, soprattutto per chi è interessato a “entrare” in questi modelli».
La mechanistic interpretability rappresenta dunque un ponte tra la comprensione scientifica dei sistemi di intelligenza artificiale e la loro governance pratica. Non si tratta solo di soddisfare una curiosità intellettuale su come funzionano questi modelli, ma di sviluppare strumenti concreti per renderli più affidabili, più sicuri e più controllabili. La possibilità di intervenire chirurgicamente sui meccanismi interni apre scenari inediti per la sicurezza informatica, permettendo potenzialmente di neutralizzare comportamenti indesiderati alla radice, anziché limitarsi a filtrarli a posteriori.
La sfida che rimane aperta riguarda il trasferimento di queste capacità agli utenti finali: come rendere accessibile questa “informazione di debug” a chi utilizza quotidianamente questi strumenti? La risposta a questa domanda determinerà in larga misura il futuro dell’interazione uomo-macchina nell’era dell’intelligenza artificiale.
Guarda il video dell’intervento completo:

Professore associato all’Università Sapienza di Roma, si occupa da oltre dieci anni di ricerca in ambito di reti neurali, sia in ambito teorico che in ambiti più pratici, con applicazioni che spaziano dalle telecomunicazioni alla medicina, fisica, e neurologia. In passato è stato molto attivo in attività di divulgazione di machine learning, tramite associazioni no-profit, Meetup, e podcast. Attualmente, è ricercatore affiliato all’INFN, junior fellow della Scuola Superiore di Studi Avanzati della Sapienza, e membro della ELLIS Society.