
Biometria della voce umana in uno scenario forense, strategico o commerciale
Negli ultimi anni la ricerca tecnico scientifica ha iniziato ad esplorare alcuni meccanismi complessi idonei a identificare una voce attraverso le c.d. “frequenze fondamentali”[1] con tecniche AI, discostandosi dalle pratiche consolidate delle scienze forensi.
La ratio è quella di “disegnare” un sistema affidabile, con uno scarto d’errore trascurabile, non aggredibile da strumenti di clonazione dell’Artificial Intelligence e, soprattutto, immediato come gli altri sistemi di identificazione biometrica.
Lo stato dell’arte dello speaker recognition secondo le metodiche tradizionali si sofferma, essenzialmente, sui principi di approccio che abbracciano metodi d’ascolto o uditivi, metodi basati sul confronto dei sonogrammi, metodi basati sull’analisi dei parametri acustico-fonetici e, infine, metodi automatici basati su codifiche del segnale vocale.
Lo speech processing
In linea generale, le tematiche oggetto del presente interesse trovano contesto nello speech processing[2] è comprendono:
“[…] speech recognition: le informazioni acustiche (a mo’ di esempio, i comandi vocali impartiti ad una macchina, come un pc o un telefono) vengono convertite in informazioni di tipo linguistico, descrivibile attraverso trascrizione in un formato di testo o comprese dal sistema informatico.
speech synthesis: consiste nella capacità di un determinato sistema di elaborazione dati, in grado di sintetizzare, quindi simulare, la voce umana con tutte le possibili inflessioni e aspetti prosodici.
speech understanding: concerne la comprensione semantica delle frasi che compongono il “parlato”, con l’ausilio di speciali algoritmi di intelligenza artificiale e di reti neurali dedicati.
speaker recognition: si interessa al riconoscimento del parlatore (l’impronta vocale è, sotto il profilo biometrico, univoca come quella digitale) con l’impiego di algoritmi di analisi numerica dei segnali[3] (ad es. la trasformata di Fourier)[4].
vocal dialog: attraverso il v.d. è possibile riprodurre in un sistema informatico le caratteristiche dialogiche fra due parlanti. Un calcolatore si occuperà al riconoscimento dell’interlocutore, all’ identificazione delle singole parole e alla comprensione del lessico nel suo insieme. Il sistema dovrà poi saper elaborare una risposta, a sua volta tradotta da un sintetizzatore vocale […]”[5].
La variabilità
Sono, poi, presenti una serie di variabilità che in ambito allo speech processing assumono rilievo e, in particolare:
“[…] variabilità acustica: i fonemi sono soggetti alla c.d. coarticulation effect, differenziandosi in base al contesto di pronuncia, producendo effetti acustici diversi tra loro. In buona sostanza, l’impronta sonora è fortemente condizionata dall’ambiente di produzione del suono […].
variabilità del parlato: i suoni sono pesantemente condizionati dallo stato emozionale del parlante, ed emessi con tonalità diverse. Più avanti si farà riferimento più articolato ad alcuni condizionamenti fisiologici che in condizione stressorie ed emozionali modificano il pattern abituale e, in particolare, quello vocale, determinato delle forme di microtremore;
variabilità del parlante: i sistemi di riconoscimento vocale devono essere rodati al fine di riuscire a riconoscere l’impronta vocale di un parlante;
variabilità linguistica: con riguardo al significato, il relativo riconoscimento è condizionato dal fatto che concetti analoghi possono trovare esplicazione attraverso frasi diverse, e ancora differente interpretazione;
variabilità fonetica: una stessa parola trova rappresentazione fonetica differente, diversificandosi nella pronuncia a seconda della provenienza geografica del soggetto parlante […]”[6].
Ultima precisazione riguarda quei rumori e interferenze in grado di pregiudicare (“sporcare”) la qualità di un reperto fonico, come il fading[7], il muffling[8], il riverbero ambientale, i rumori di fondo, la c.d. coda GSM[9] e le interferenze R/F[10], spesso oggetto di interesse in uno scenario peritale forense[11].
Andando, adesso, al core di questo approfondimento, gli approcci più recenti sull’automatismo di riconoscimento della voce si sono soffermati sulla scelta di algoritmi idonei a confrontare e riconoscere le voci, prediligendo altri aspetti delle frequenze fondamentali.
Altezza della voce
Dette componenti, intese anche “altezza della voce”, variano in modo più accentuato con età e sesso: i bambini, ad esempio, registrano una frequenza che va dai 250 ai 350 Hz, mentre le donne tra i 150 e i 250 Hz e gli uomini dai 70 ai150 Hz.
Alcune aziende, nel cimentarsi con questo approccio biometrico, hanno esplorato le possibili applicazioni di impiego di un modello di identificazione automatica di un’impronta vocale, anche in un’ottica di trattamento di dati sensibili in armonia con le linee quadro fissate dal Regolamento (UE) 2016/679 (GDPR).
Soluzioni applicative
Un primo impiego riguarda l’ attivazione di un IOT tramite un’impronta vocale, principalmente destinato a sistemi d’arma/utensili provvisti di caricatore[12]; aree riservate, vani blindati, strutture tattiche/strategiche, ecc.
Ma impiegabile, anche, come consenso di moduli per la domotica, l’automotive, l’ e-commerce e l’ e-banking, grazie anche ad evolute architetture in grado di rilevare liveness detection[13], sia in relazione a tentativi di spoofing[14], di voice clone[15] o di montaggi digitali di frammenti audio, analizzando anche aspetti prosodici del parlato, idonei tra l’altro a registrare aspetti di alterazione del pattern individuale ed utili a rilevare dinamiche stressorie[16], così da rendere più robusto il sistema anche in caso di coercizione fisica.
Un ulteriore ambito applicativo riguarda l’interfaccia del sistema di identificazione biometrica di una voce, con altre soluzioni idonee a rilevare molteplici linguaggi ed alla trascrizione simultanea multilanguage; quindi una soluzione di riconoscimento sia intra che inter parlatore.
Data Analysis
Detto strumento di speaker recognition viene, altre volte, abbinato a soluzioni di data analysis in grado di processare una gestione massiva di dati, così da poter, ad esempio, ricercare una singola voce dentro un contenitore di reperti (come un archivio giudiziario, le registrazioni di una sala operativa, quelle di un call center, ecc.), identificare un target vocale oggetto di segnalazione/interesse all’atto della sua presenza sul sistema di ascolto o, ancora, selezionare all’interno di un flusso di comunicazione una parola, un lessico, un repertorio linguistico, ecc[17].
Isoglosse
Quindi, anche, uno strumento di filtraggio e di individuazione di isoglosse[18], quindi in grado di delimitare specifiche aree geografiche di diffusione di un determinato fenomeno linguistico[19].
L’interesse verso l’individuazione di un pattern biometrico era inizialmente nato per esigenze investigative e forensi, lo si voglia per identificare un offender o, altrettante volte, per dare un nome alla vittima di un crimine.
Pattern biometrico
Già nell’800 Francis Galton sviluppò (1888) lo studio sistematico delle impronte papillari, individuando alcuni punti caratteristici definiti definiti minutiae, dettagli delle creste papillari che rendono ogni impronta digitale unica e irripetibile. In Italia, l’introduzione delle impronte digitali nelle indagini fu opera di Salvatore Ottolenghi, medico e allievo di Cesare Lombroso, il quale ebbe comunque un ruolo pionieristico nella proposta di metodi scientifici per l’identificazione dei criminali.
Le ricerche scientifiche si sarebbero estese negli anni a seguire verso altri elementi caratteristici di identificazione di un essere umano: ad esempio la geometria del volto, gli elementi caratteristici dell’iride o, in un contesto autoptico, l’impronta dentaria, la presenza di protesi ortopediche e quanto altro.
L’enrollment
Le nuove tecnologie, e le sempre crescenti richieste di mercato, hanno indotto i ricercatori ad affinare tecniche di enrollment (registrazione) e riconoscimento non più – e non soltanto – per esigenze investigative, forensi o per protocolli identificativi di sicurezza, bensì per tutte quelle esigenze di applicazione commerciale di cui abbiamo fatto cenno.
Lasciando, per il momento, da parte le questioni relative alla falsificazione di un pattern identificativo, il problema più delicato riguarda, essenzialmente, la criticità relativa al momento di riconoscimento presso un varco oggetto di pregresso enrollment.
E, allora: può una persona superare un consenso biometrico contro la propria volontà?
E’ possibile, ad esempio, imporre ad un individuo di apporre la propria impronta papillare, o costringerlo a presentarsi davanti un varco per l’identificazione attraverso l’iride o la geometria del volto?
Da alcuni studi criminalistici è emerso che, ad esempio, in diversi contesti carcerari i detenuti abbiano cercato di distruggere le proprie impronte con ablazione dell’area dei polpastrelli o, addirittura, arrivando a mutilazioni per evitare un’ identificazione biometrica.
Altrettante volte, negli stessi contesti sociali, il continuo sequestro di cutter e cucchiaini da caffè ha palesato l’espediente di procedere all’amputazione di dita degli addetti alla vigilanza addirittura arrivando all’estrazione di orbite oculari, al fine di forzare un varco di identificazione biometrica in caso di mancato consenso da parte dell’addetto all’apertura.
Spoofing
Le tecnologie sempre in continua evoluzione hanno, almeno in parte, contrastato detto espediente, con continui affinamenti delle procedure di liveness detection, ad esempio attivando un ulteriore sistema di rilevamento della temperatura e della venatura del palmo, che impediscono l’uso di arti amputati o repliche inerti.
Le procedure identificative più elementari sono, poi, ingannate da sistemi di clonazione dell’impronta facciale, così da non rendere detto strumento altamente attendibile ed efficace; un esempio frequente è quello degli smartphone, dove la perfomance aumenta nel caso di identificazione con sistemi ottici 3D, rimanendo critica per tutti quei sistemi che, con l’impiego di fotocamere 2D, tendono ad essere ingannati di fronte a riproduzioni fotografiche, da qui inducendo gli utenti a modalità identificative a più fattori.
I sistemi più evoluti di riconoscimento vocale integrano, anche, sofisticate modalità di rilevamento delle falsificazioni basate su componenti A.I., idonei a individuare tentativi di spoofing.[20]
Pattern e alterazioni stressorie
Ma, rispetto all’identificazione dell’impronta papillare, dei contorni dell’iride o della geometria del volto, l’identificazione attraverso la biometria della voce consente di poter addestrare il sistema a riconoscere, anche, anomale alterazioni del pattern abituale dell’individuo come nel caso di fenomeni stressori indotti da coercizione o di menzogna.
“[…] Ciò determina un’alterazione del pattern abituale, con inusuali tratti cinesici e gestuali, incremento dello stato d’ansia per l’essere scoperto, così evidenziando ulteriori segni di manipolazione dovuti all’attivazione del sistema nervoso simpatico, attraverso cui saranno evidenziate modifiche neurofisiologiche ed elevazione brusca dell’ormone dello stress[21].
[…] (anche il) rapporto tra individuo ed ambiente (è) in grado di determinare frequenti interazioni di stress, che hanno come generica conseguenza uno stato d’ansia. Taluni elementi ambientali, con ciò intendendosi anche esperienze, rapporti interpersonali e situazionali, detti stressors, determinano una sollecitazione sull’organismo e subiscono sempre un’elaborazione di tipo cognitivo, da cui dipende generalmente la reazione della persona, e da qui un’alterazione dell’equilibrio tra individuo ed ambiente a cui consegue il disagio definito stress.
La condizione di stress determina l’attivazione di un circuito composto da strutture cerebrali e da una ghiandola endocrina, il surrene[22], il quale aumenta la secrezione di cortisolo; questo ormone, anche conosciuto come ormone dello stress, è particolarmente indicativo per rilevare la menzogna nel corso di un’intervista, in quanto induce, tra l’altro, un aumento della gittata cardiaca e dei valori glicemici[23].
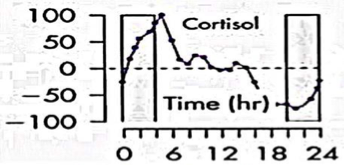
Lo stress indotto dalla menzogna ha, inoltre, per effetto dei microtremori della voce, dovuti al minore afflusso di sangue verso le corde vocali così da determinare la tensione dei muscoli striati della laringe inducendo, per contro, un’improvvisa affluenza di sangue in alcune parti del viso, ed in maniera peculiare vicino gli occhi.
Questi, come altri indizi, saranno oggetto di monitoraggio investigativo nel corso del colloquio tecnico al fine di rilevare la presenza di menzogne[25]. […]”[26].
Strong authentication
Del resto, anche il nostro Garante per la protezione dei dati personali e l’Agenzia per la Cybersicurezza Nazionale (ACN) si sono uniformati alla necessità di procedere a modalità di strong authentication in taluni casi, stabilendo che i fattori di autenticazione devono essere scelti tra tre categorie: la conoscenza (cioè qualcosa che solo l’utente sa, come ad esempio una password, un PIN, ecc.); il possesso (qualcosa che solo l’utente possiede, come un token fisico, uno smartphone per ricevere OTP via SMS, un’app di autenticazione, una smart card); inerenza (ciò che caratterizza l’utente, come un pattern biometrico di identificazione).
Si tratta di misure che il Garante e l’Agenzia prescrivono obbligatoriamente per specifiche categorie di trattamenti ad alto rischio, o laddove sia necessario procedere alla protezione di credenziali prevedendo che, anche in presenza di autenticazione forte, i titolari del trattamento debbano adottare misure crittografiche sicure per la conservazione delle password, poiché gli utenti potrebbero riutilizzarle per altri servizi meno protetti.
L’artificial Intelligence
Rispetto alle metodiche classiche, attraverso l’apprendimento automatico (Machine Learning) è possibile istruire le macchine al fine di acquisire competenze, metabolizzare dati, riconoscere modelli e avviare processi decisionali, con un intervento umano minimo, acquisendo al contempo elevati livelli di performance con grande risparmio di risorse e di tempo.
Vi è poi un livello più profondo di apprendimento (Deep Learning) che impiega diverse reti neurali artificiali con molti strati (profondi) per apprendere autonomamente da grandi quantità di dati, replicando le funzioni del cervello umano, così da essere in grado di riconoscere pattern complessi o risolvere problemi articolati, come il riconoscimento di immagini, la traduzione automatica e la guida autonoma, processando informazioni in gerarchie di concetti sempre più astratti.
L’embedding
Ma la rivoluzione determinata dai modelli di IA consiste nella capacità di riconoscere un individuo a prescindere dalla lingua standard/vernacolare parlata o dal contenuto del discorso; ciò grazie alla possibilità di impiegare moderni algoritmi di riconoscimento della voce attraverso caratteristiche biometriche univoche di un parlante a prescindere dalla lingua, basandosi su modelli statistici e rappresentazioni numeriche della voce (embedding)[27].
Alcuni aspetti critici, come possibili bias dovuti ai processi di addestramento o le sempre crescenti minacce di deepfake vocali, rimangono questioni aperte oggetto di approfondimento e ricerca continua per mitigarne il rischio. [28]
La complessa evoluzione ha fatto i conti anche con l’approccio forense e investigativo, non trascurabile, inducendo gli addetti ai lavori alla continua acquisizione di nuove competenze che, dalla linguistica tradizionale, si sono evolute abbracciando nozioni di machine learning, linguistica computazionale, reti neurali, e capacità di lettura critica delle metriche fornite dai sistemi automatici.
La Likelihood Ratio e i dataset
Attraverso la LR[29] (cioè il rapporto di verosimiglianza) è possibile valutare, in un contesto forense, il livello di probabilità di un riscontro vocale e si basa sulla
possibilità di mettere in raffronto un reperto fonico di interesse con un consistente campione di reperti similari.
Esistono alcuni dataset[30], fruibili pubblicamente[31], convenzionalmente utilizzati per addestramenti iniziali di modelli neurali[32], seppur non sempre ricchi della popolazione di riferimento interessata ad un determinato caso di studio, ciò per via della poco approfondita campionatura di micro isoglosse, fatte di infinite varianti linguistiche e di inflessioni dialettali[33].
Va ulteriormente precisato che, alla base di un processo di Likelihood Ratio, non vi è il solo raffronto di un dataset della popolazione di riferimento, ma è necessario arricchire la procedura con i pattern caratteristici del soggetto attenzionato, a partire dall’età, al sesso, a possibili alterazioni dovute a stati di salute, clinici[34], alle condizioni foniche di acquisizione del reperto, fono alle modalità di registrazione e di eventuale compressione del dato.
Sono in itinere proprio per questa ragione[35], progetti scientifico-accademici di acquisizione di dataset circoscritti a specifiche comunità linguistiche, frequentemente interessate ad attenzioni investigative o d’intelligence[36].
Intra e Inter parlatore
Il riconoscimento di una o più voci attraverso gli strumenti dell’A.I. si rifà al funzionamento del cervello umano, in grado di isolare e riconoscere una voce tra milioni di reperti simili.
Si tratta dell’ascolto selettivo, introdotto negli anni ’50 da Colin Cherry[38], coniando il concetto di “effetto cocktail party”, cioè la capacità del cervello umano[39] (di concentrarsi su una singola voce o conversazione, isolandola dal rumore di fondo in un ambiente rumoroso o affollato.
Questo fenomeno, sfrutta l’attenzione selettiva, permettendo di filtrare i suoni irrilevanti e riconoscere stimoli rilevanti, come il proprio nome, anche a distanza.

Oggi i modelli di artificial intelligence sono in grado di emulare il principio biologico studiato da Cherry attraverso reti neurali profonde e tecniche di apprendimento automatico; si tratta di una elaborazione che nel sistema nervoso centrale avviene attraverso un’elaborazione multisensoriale che impegna l’area di Wernicke[41] (una regione cruciale nel cervello, solitamente nell’emisfero sinistro, fondamentale per la comprensione del linguaggio parlato e scritto, gestendo il significato delle parole e la semantica).
L’area di Wernicke e l’A. I.
È qui che vengono analizzati timbrica, frequenza e modulazione di una voce, riuscendo a identificare una voce anche in contesti dove rumore, intensità o tono potrebbero pregiudicarne l’intellegibilità completa.
Il ruolo dell’A..I. si svolge attraverso l’impiego di reti neurali convolutive e ricorrenti, in grado di estrarre pattern vocali rilevanti e di memorizzare schemi frequenti per addivenire all’identificazione[42].
“[…] I modelli neurali impiegati nell’identificazione vocale si basano su tecniche di classificazione, confronto e apprendimento di rappresentazioni vocali note come embeddings[43].
Gli embeddings vocali sono vettori numerici che codificano le caratteristiche distintive della voce di un individuo, facilitando il confronto tra campioni diversi mediante metriche di similarità.
Questi vettori vengono generati da architetture come i modelli basati su Transformer o reti siamesi, che apprendono a minimizzare la distanza tra campioni della stessa voce e a massimizzarla tra voci differenti.
L’uso di metriche avanzate, come la distanza coseno o la distanza euclidea modificata, permette di affinare ulteriormente la capacità di riconoscimento, migliorando l’accuratezza anche in condizioni di rumore o distorsione.
Un aspetto cruciale dell’identificazione vocale[44] è la capacità di autenticare un individuo indipendentemente dal contenuto del discorso.
Mentre i sistemi di riconoscimento del parlato si concentrano sulla trascrizione del testo pronunciato, l’identificazione biometrica vocale si focalizza sulle caratteristiche fisiche e comportamentali uniche del parlante.
Ciò consente di verificare un’identità senza la necessità di una frase predefinita, rendendo il sistema più sicuro contro tentativi di imitazione o attacchi basati su registrazioni[…]”[45].
Note
[1] Cioè il tono di base prodotto dalla vibrazione delle corde vocali, misurata in Hertz (Hz), che cambia in base a lunghezza, tensione e massa delle corde.
[2] www.ghostcomputerclub.it
, Introduzione allo speech processing, di Pellegrinetti G., settembre 2001: […]Lo schema descrive un sistema di speech processing ideale dove tutte le componenti funzionano correttamente e cooperano fra loro per ottenere un risultato. Normalmente, nei sistemi in commercio, sono presenti solo alcune di queste componenti (ad esempio manca il riconoscimento del linguaggio). L’utente emette delle istruzioni vocali tramite un trasduttore (microfono, cornetta telefonica,…) che vengono intercettate dai vari moduli di riconoscimento. Il modulo di riconoscimento del linguaggio si occupa di individuare la lingua in cui parla l’utente.
Tale processo è molto complesso e si basa sulla presenza di inflessioni vocali presenti in una lingua piuttosto che in un’altra (in pratica cerca di individuare l’accento con cui l’interlocutore parla). Dopo aver individuato la lingua è necessario individuare l’interlocutore. Ogni persona, come abbiamo già detto in precedenza, ha una specifica impronta vocale. Analizzando questa impronta e confrontandola con quelle presenti in archivio, il sistema (nello schema: riconoscimento del parlante) è in grado di individuare un utente con una precisione molto elevata. Il passaggio successivo consiste nel riconoscere i comandi impartiti: il modulo di riconoscimento della voce elabora le informazioni vocali ricevute e le confronta con le “impronte” memorizzate sul database.
Il risultato finale di questa operazione è un insieme di parole che possono poi essere successivamente elaborate. Un sistema completo si speech processing, infatti, possiede al suo interno un modulo di intelligenza artificiale (rappresentato nello schema dalle componenti “comprensione del linguaggio, rappresentazione della conoscenza e contesto del discorso) che ha lo scopo di “comprendere” le frasi pronunciate dall’utente basandosi su sofisticati meccanismi di analisi sintattica e grammaticale. Il risultato di questa operazione può essere l’esecuzione di un comando da parte del computer (controllo vocale) o l’attivazione di un altro software che in base al testo passato come parametro genera una risposta da fornire all’utente.
Sono esempi di questa tecnologia gli strumenti derivati dal vecchio programma Eliza (psicologo virtuale) tra i quali troviamo strumenti di interrogazione vocale a basi di dati, strumenti di analisi dei testi, macchine della verità. Nel caso in cui il sistema debba fornire una risposta vocale all’utente, deve essere attivato un modulo di sintesi vocale. Tale modulo (generatore del linguaggio) prende in input un testo e genera la sequenza di suoni che devono essere riprodotti successivamente tramite una scheda audio. Un sistema completo di questo tipo esiste solo in alcuni laboratori di ricerca. Lo scopo finale è quello di fornire un ambiente completo che consenta la comunicazione uomo-macchina tramite l’utilizzo del comune linguaggio verbale […]”.
[3] Ivi, “[…] Lo speech recognition é il processo di conversione di segnali acustici, catturati da un microfono o da un telefono, in un insieme corrispondente di parole. Il risultato di questo processo può poi essere utilizzato per controllare tramite voce un sistema informatico, per eseguire data-entry (es. dettatura di un testo al nostro word processor preferito) o come input per sistemi più complessi come i sistemi di comprensione dei testi che utilizzano sofisticati algoritmi di intelligenza artificiale per districarsi fra i vari significati che una frase o un testo possono assumere. Alcuni dei parametri che caratterizzano un sistema di riconoscimento vocale sono i seguenti: Speaking Mode: rappresenta la modalità di lettura delle parole.
Gli algoritmi di riconoscimento meno recenti richiedono di separate le parole con una breve pausa in modo da consentire al software di individuare con esattezza l’inizio e la fine di ogni singola parola. I sistemi più recenti, invece, sono in grado di separare automaticamente le parole consentendo allo speaker di parlare normalmente senza dover inserire delle pause innaturali fra le parole. Speaking Style: rappresenta la modalità con cui lo speaker emette le parole: sta parlando spontaneamente (come durante il discorso fra due persone) o sta leggendo un testo? A seconda della modalità di emissione dei suoni lo strumento deve applicare algoritmi differenti per individuare i diversi fonemi.
Enrollment: Il sistema di riconoscimento e speaker dependent o speaker independent. I sistemi meno recenti richiedono di essere addestrati per riconoscere un determinato utente.
L’addestramento avviene facendo leggere allo speaker un centinaio di frasi. In tal modo il software é in grado di identificare l’impronta vocale dei singoli fonemi e di creare un’immagine degli stessi su un archivio. L’accuratezza del riconoscimento aumenta in modo proporzionale con le sedute di addestramento eseguite. Il problema di questo approccio é che il software é in grado di colloquiare solamente con gli utenti per cui é stato addestrato.
I sistemi più recenti (sono esclusi gli strumenti domestici come Via Voice e Dagon Dictate), soprattutto quelli ad utilizzo pubblico come i centralini intelligenti (vedi servizio 190 Omnitel) o i chioschi multimedidiali di ultima generazione devono essere indipendenti dallo speaker. Gli algoritmi utilizzati, comunque, non sono ancora infallibili e producono numerosi errori. Tali sistemi cercano di individuare i fonemi in base all’intercettazione di similitudini fra un modello memorizzato e il fonema pronunciato dall’interlocutore.
Purtroppo basta cambiare inflessione nella voce per ingannare questi sistemi. Vocabolario: La maggior parte dei sistemi di riconoscimento vocale si basa su un vocabolario predefinito di parole che viene adattato all’utente mediante il procedimento di addestramento descritto in precedenza. Un buon sistema di riconoscimento si basa normalmente su un vocabolario di almeno 20000 parole. Modello del linguaggio: I sistemi più datati si basano su un modello del linguaggio costruito sul concetto degli automi a stati finiti. Un sistema di questo tipo non é molto flessibile e si basa sul riconoscimento delle singole parole in base al vocabolario in suo possesso.
L’accuratezza del riconoscimento, in questo caso, si riduce enormemente quando si dettano frasi che non utilizzano correttamente le regole grammaticali. I sistemi più recenti utilizzano un approccio sensibile al contesto (context-sensitive). Grazie alla presenza di complessi algoritmi di intelligenza artificiale sono in grado di individuare e di riconoscere parole non presenti sul vocabolario e sono in grado di ricostruire una frase basandosi sul presunto significato della stessa […]”.
[4] Iacovelli G., Rosi G., La trasformata di Fourier, abstract, Università Roma 3, Roma (2012): “In parole povere la trasformata di Fourier consente di scomporre un’onda qualsiasi, anche molto complessa e rumorosa (un segnale telefonico o televisivo, la musica, la voce!) in piú sotto-componenti, un po’ come attraverso la chimica si puó scomporre un cibo nei suoi sottoelementi così da capirne la reale composizione. Piú precisamente la trasformata di Fourier permette di calcolare le diverse componenti (ampiezza, fase e frequenza) delle onde sinusoidali che, sommate tra loro, danno origine al segnale di partenza. Storicamente queste due equazioni sono nate dalla brillante mente di Jean Baptiste Joseph Fourier (1768-1830) quasi duecento anni fa, nel 1822”.
[5] Di stefano M., Le trascrizioni nel processo penale. Manuale dei periti, consulenti e polizia giudiziaria, Città del Sole editore, Reggio Calabria (2023) pagg. 53-55.
[6] Ibidem.
[7] Eccessiva amplificazione.
[8] Ovattamento del microfono occultato.
[9] Si tratta di una frequenza di disturbo dovuta alla portante del modulo GSM che, in condizioni di cattiva ricezione, tende ad amplificare automaticamente la trasmissione del reperto fonico.
[10] Come nel caso in cui la trasmissione R/F sia disturbata da campi magnetici nella vicinanza, come motori di elettrodomestici, motorizzazioni a due tempi, inquinamenti elettromagnetici della zona di interesse, ecc.
[11] Di Stefano M., Sociologia della comunicazione quale strumento d’indagine. I dettagli smarriti nelle intercettazioni”, Altalex quotidiano d’informazione giuridica”, 17 aprile 2013: “[…]Sotto il profilo fonetico, poi, l’abilità del tecnico nel definire la qualità del reperto fonico e la sua attendibilità – rilevando o isolando i vari disturbi di acquisizione dovuti al fading ( cioè l’amplificazione del sistema di registrazione), al muffling (l’ovattamento del microfono occultato), al riverbero ambientale e ai rumori di fondo – dovrebbe trovare commisurata rispondenza in fase trascrittiva ed interpretativa del reperto, ove la trasformazione del parlato allo scritto sarebbe meritevole di indispensabili precisazioni di tipo etnolinguistico.
Ciò in quanto la situazione comunicativa viene spesso acquisita in forma esclusivamente dialettale, con frequenti code swiching, salti linguistici, cambi d’argomento, sott’intesi ed espressioni gergali. La sua documentazione, a prescindere da possibili precisazioni extralinguistiche sulla cinesica, mimica e postura, non trova, solitamente, adeguata rappresentazione paraverbale, in quanto difficilmente la trasposizione, dal parlato allo scritto[1], di una conversazione di interesse giudiziario reca anche dettagli di tipo prosodico, come l’enfasi, le pause, il ritmo, l’intonazione, o ancora quei microtremori significativi di una situazione di distress tra i conversanti[…]”.
[12] Si tratta, nello specifico, di un patent pending USA e Italia registrato dalla società Pragma Etimos, di cui chi scrive è coinventore con altri esperti di quell’azienda.
[13] Cioè il rilevamento della vivacità.
[14] Di falsificazione.
[15] Di clonazione di una voce.
[16] Attraverso strumenti di Voice stress analyzer.
[17] Ad esempio: quante persone hanno segnalato una specifica avaria? Chi ha fatto riferimento alla città di Roma? Chi parlava con spiccato accento dell’agrigentino?
[18] Le isoglosse a lovo volta possono distinguersi in: isofona, che riguarda la fonetica (es. diversa pronuncia di una vocale); isolessa, che riguarda il lessico (es. uso di termini diversi per lo stesso oggetto); isomorfa, che riguarda i tratti morfologici (es. diverse desinenze dei verbi); isosema, che riguarda differenze di significato per la stessa parola.
[19] Ad esempio: isolare tutti i parlanti provenienti dall’area subsahariana.
[20] Wang Z., Hansen J. H. L., Toward Improving Synthetic Audio Spoofing Detection Robustness via Meta-Learning and Disentangled Training With Adversarial Examples, fonte: https://arxiv.org/abs/2408.13341
[21] Snyder M., The self‐monitoring of expressive behavior. Journal of Personality and Social Psychology, (1974).
[22] Asse ipotalamo‐ipofisi‐surrene.
[23] Il cortisolo è un ormone prodotto dalle cellule della fascicolata del surrene in risposta all’ormone ipofisario ACTH. L’ACTH è dunque il precursore del cortisolo. Il cortisolo viene spesso definito “ormone dello stress” perché la sua produzione aumenta, appunto, in condizioni di stress psico‐fisico severo e, nel caso di interesse alla presente disamina, nel caso di manipolazione di risposta ad un questionario. Con la sua azione, quest’ormone tende ad inibire le funzioni corporee non indispensabili nel breve periodo, garantendo il massimo sostegno agli organi vitali. Per detta ragione il cortisolo determina, tra l’altro, un aumento della gittata cardiaca e dei valori glicemici.
[24] Fonte: http://francescobarbato.wordpress.com/tag/cortisolo/
.
[25] Musso A., Muzzo G., Gadoni O., Il linguaggio segreto del corpo. Il significato dei gesti e dei comportamenti umani nella relazione con gli altri, Jackson libri (2000).
[26] Di Stefano M., Fiammella B., Profiling. Tecniche e colloqui investigativi, profili d’Intelligence, Altalex editore, Montecantini Terme (2013).
[27] Cioè la rappresentazione di dati complessi, siano essi parole, immagini o interi documenti, sotto forma di vettori di numeri reali in uno spazio multidimensionale.
[28] Richmond K., AI, Machine Learning, and International Criminal Investigations: the lessons from Forensic Science, abstract (2020).
[29] Morrison G., The likelihood-ratio framework and forensic evidence in court: A response to R v T., The International Journal of Evidence & Proof, 16(1), 1–29 (2012).
[30] VoxCeleb: dataset di parlato pubblico sviluppato da Nagrani A., Chung J. S., Zisserman A., in https://www.robots.ox.ac.uk/~vgg/data/voxceleb/
https://www.isca-archive.org/interspeech_2017/nagrani17_interspeech.html
[31] NIST Speaker Recognition Evaluation (SRE): benchmark internazionale per la valutazione dei sistemi di riconoscimento del parlante, in https://www.nist.gov/itl/iad/mig/speaker-recognition
[32] Tra i dataset più noti si richiama VoxCeleb o il benchmark internazionale NIST Speaker Recognition Evaluation (SRE).
[33] Toussaint Hutiri W., Yi Ding A., Bias in Automated Speaker Recognition, Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency (2022)
[34] Si consideri, ad esempio, un soggetto sottoposto ad intervento chirurgico di una parte dell’apparato fonatorio o che, a seguito di un incidente, abbia subito una deformazione o perdita del proprio impianto dentario, successivamente alla data di acquisizione dei un reperto fonico a questi attribuibile (un caso di scuola è quello relativo alle complesse perizie foniche effettuate nei giudizi di merito in relazione all’omicidio di P. M., avvenuto a Reggio Calabria il 17 settembre 2011. In quel caso uno degli imputati C. D., era stato sottoposto ad intervento chirurgico facciale che aveva in parte alterato il suo pattern fonetico, venendo poi assolto per la mancata identificazione della sua voce tra i reperti oggetto di prova.
[35] González-Rodríguez J., Fierrez J., Ortega-Garcia J., Forensic identification reporting using automatic speaker recognition systems. 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, (2003), Proceedings. (ICASSP ’03). 2 (2003): II-93.
[36] https://it.linkedin.com/posts/pragma-etimos-s-r-l-_pragmaetimos-criminologia-intelligenzaartificiale-activity-7318898393446006786-m3HW: “ […] Nasce una collaborazione strategica tra tecnologia e scienze criminologiche. Siamo orgogliosi di annunciare l’accordo tra Pragma Etimos srl e l’Istituto Italiano di Criminologia ad ordinamento universitario di Vibo Valentia. Un progetto ambizioso che punta a mappare le isoglosse italiane, raccogliendo campioni vocali sul territorio per definire con precisione la distribuzione di dialetti e peculiarità linguistiche.
Un’iniziativa unica nel suo genere, mai tentata prima in Italia su scala strutturata. Il nostro Paese è infatti uno dei territori più ricchi e complessi dal punto di vista linguistico, con una straordinaria varietà di dialetti e micro-varianti locali. Solo l’area di Vibo Valentia offre una densità di varianti dialettali altissima, e lo studio di queste specificità fornirà dati preziosi per perfezionare i modelli AI e costruire una mappatura scientifica accurata delle isoglosse.
L’obiettivo è quello di realizzare di dataset relativi a micro-macro aree geografiche per sviluppare nuovi modelli AI di Speaker Identification e Speech Transcription a disposizione delle autorità governative per esigenze di sicurezza e intelligence, nonché per il mondo commerciale e turistico ad ampio spettro di applicazione anche in abbinamento a strumenti di Internet of Things. ”
Non è un’iniziativa isolata, ma parte di una strategia che da tempo ci vede impegnati nello sviluppo di tecnologie audio forensi brevettate e già operative al fianco delle istituzioni. La collaborazione con l’Istituto rafforza un percorso solido e mirato. Siamo felici di continuare a crescere su questa strada e per questo aperti a valutare il contributo di chi, nel mondo dell’innovazione e della ricerca, voglia credere in questa visione.” […]”.
[37] Fonte: https://www.reddit.com/r/MapPorn/comments/szx1f2/map_of_dialects_of_arabic_in_the_middle_east_and/?tl=it
[38] Cherry C., Some Experiments on the Recognition of Speech, with One and with Two Ears, The journal of the acoustical society of America, volume 25, number 5 september, 1953, pag. 975-976: “[…] The first set of experiments relates to this general problem of speech recognition: how do we recognize what one person is saying when others are speaking at the same time (the “cocktail party problem”)? On what logical basis could one design a machine (“filter”) for carrying out such an operation?
A few of the factors which give mental facility might be the following: (a) The voices come from different directions. (b) Lip-reading, gestures, and the like. (c) Different speaking voices, mean pitches, mean speeds, male and female, and so forth. (d) Accents differing. (e) Transition probabilities (subject matter, voice dynamics, syntax.). All of these factors, except the last (e), may, however, be eliminated by the device of recording two messages on the same magnetic-tape, spoken by the same speaker. ‘The result is a babel, but nevertheless the messages may be separated.[…]”.
[39] Ma anche diversi animali sono in grado di riconoscere una voce “familiare” rispetto ad altre voci simili.
[40] Fonte: https://rolandociofi.blogspot.com/2017/07/attenzione-effetto-cocktail-party.html
[41] Binder J. R. The Wernicke area: Modern evidence and a reinterpretation. Neurology. 2015 Dec 15;85(24):2170-5. doi: 10.1212/WNL.0000000000002219.
[42] Keshishian M., Mischler G., Thomas S., Kingsbury B., Bickel S., Mehta A. D., Mesgarani N., Parallel hierarchical encoding of linguistic representations in the human auditory cortex and recurrent automatic speech recognition systems; bioRxiv 2025.01.30.635775; doi: https://doi.org/10.1101/2025.01.30.635775
[43] Batra A., Saraswat P., Agrawal R. and Yadav K., Employing Neural Networks for Speech Recognition, 2024 IEEE International Conference on Computing, Power and Communication Technologies (IC2PCT), Greater Noida, India, 2024, pp. 1279-1283, doi: 10.1109/IC2PCT60090.2024.10486702.
[44] Singh J. N., Sirohi S. and Mall S., Use of Artificial Intelligence in Voice Recognition, 2023 5th International Conference on Advances in Computing, Communication Control and Networking (ICAC3N), Greater Noida, India, 2023, pp. 995-998, doi: 10.1109/ICAC3N60023.2023.10541456.
[45] Di Stefano M., Rubiu D., Riconoscimento vocale biometrico: quando la voce diventa password, Agenda Digitale, 8 maggio 2025.

Dottore in Giurisprudenza, in Comunicazione Internazionale, specialista in Scienze delle Pubbliche Amministrazioni ed esperto in Criminologia, è un appartenente ai ruoli della Polizia di Stato.
Si interessa da oltre venti anni di tecnologie avanzate nelle intercettazioni audio video e localizzazioni, con approfondite ricerche nel settore della comunicazione in ambito investigativo e forense.
E’ esperto di balistica a tiro curvo, di topografia e cartografia militare, di analisi e profiling, con specializzazioni in campo nautico, subacqueo e nel settore delle operazioni investigative speciali sotto copertura.
Ha maturato esperienza trentennale nella P.A. presso i Ministeri della Difesa, del Tesoro ed Interno, è stato formatore e componente di comitati scientifici di alcuni atenei, scuole internazionali di management e di riviste di informazione e formazione giuridica, nel settore delle scienze criminologiche applicate alle investigazioni, all’intelligence ed al contrasto al terrorismo.





