

Le nuove sfide di cyber security per l’Intelligenza Artificiale: la mappatura dell’ecosistema e la tassonomia delle minacce
Introduzione
L’Intelligenza Artificiale (IA) ha guadagnato terreno negli ultimi anni facilitando il processo decisionale intelligente e automatizzato in tutta l’estensione degli scenari di implementazione e delle aree applicative. Stiamo assistendo a una convergenza di diverse tecnologie (ad es. Internet of things, robotica, tecnologie dei sensori, ecc.) e una crescente quantità e varietà di dati, nonché le loro nuove caratteristiche (ad es. dati distribuiti) per utilizzare l’IA su larga scala.
Nel contesto della cyber security, l’IA può essere vista come un approccio emergente e, di conseguenza, le tecniche di IA sono state utilizzate per supportare e automatizzare le operazioni rilevanti, ad esempio il filtraggio del traffico, l’analisi forense automatizzata, ecc. Sebbene indubbiamente vantaggioso, non si dovrebbe eludere il fatto che l’IA e la sua applicazione, ad esempio, al processo decisionale automatizzato, specialmente in implementazioni critiche per la sicurezza come veicoli autonomi, produzione intelligente, eHealth, ecc., può esporre individui e organizzazioni a rischi nuovi e talvolta imprevedibili e può̀ aprire nuove vie di attacco metodi e tecniche, oltre a creare nuove sfide in materia di protezione dei dati.
Inoltre, è ormai chiaro come l’Intelligenza Artificiale sta influenzando sempre più la vita quotidiana delle persone e svolge un ruolo chiave nella trasformazione digitale attraverso le sue capacità decisionali automatizzate. I vantaggi di questa tecnologia emergente sono significativi, ma lo sono anche le preoccupazioni. È quindi necessario evidenziare il ruolo della cyber security nello stabilire l’affidabilità e la diffusione di un’IA affidabile.
Quando si considera la sicurezza nel contesto dell’IA, è necessario essere consapevoli del fatto che le tecniche e i sistemi di IA che utilizzano l’IA possono portare a risultati imprevisti e possono essere manomessi per manipolare i risultati attesi.
Pertanto, è essenziale proteggere l’IA stessa tramite misure di sicurezza. In particolare, è importante:
- capire cosa deve essere messo in sicurezza (gli asset soggetti all’IA minacce specifiche e modelli contraddittori);
- comprendere i relativi modelli di governance dei dati (compresa la progettazione, valutazione e protezione dei dati e del processo di addestramento dei sistemi di IA);
- gestire le minacce in un ecosistema multipartitico in modo completo utilizzando modelli e tassonomie condivisi;
- sviluppare controlli specifici per garantire che l’IA stessa sia sicura.
Il quadro normativo comunitario ed italiano dell’IA
L’Unione Europea ha compreso sin da subito l’importanza che ricopre l’Intelligenza Artificiale all’interno della società. Pertanto, nel dicembre 2018 la Commissione europea ha adottato il “Coordinated Plan on Artificial Intelligence” con l’obiettivo di accrescere le sinergie tra Stati membri e istituzioni europee. Più precisamente, la Commissione ha evidenziato la necessità per gli stati membri di adottare una strategia nazionale di AI. Successivamente, nell’aprile 2019, la Commissione ha istituito un gruppo di esperti ad alto livello che ha pubblicato orientamenti per un’IA affidabile, pubblicando una comunicazione in cui accoglie con favore i sette requisiti fondamentali individuati negli orientamenti del gruppo di esperti ad alto livello:
- intervento e sorveglianza umani;
- robustezza tecnica e sicurezza;
- riservatezza e governance dei dati;
- trasparenza;
- diversità, non discriminazione ed equità;
- benessere sociale e ambientale;
- accountability.
Inoltre, è meritevole ricordare il “White Paper on AI” promosso nel febbraio 2020 dalla Commissione Europea, la cui finalità è la creazione di un ecosistema di eccellenza e di fiducia nell’Intelligenza Artificiale, così ponendo l’Europa all’avanguardia nella regolamentazione di questo settore.
Nel dettaglio, gli elementi primari di tale documento sono i seguenti:
- il quadro strategico che stabilisce misure per allineare gli sforzi a livello europeo, nazionale e regionale. Tramite un partenariato tra il settore pubblico e privato, l’obiettivo di tale quadro è mobilitare risorse per conseguire un “ecosistema di eccellenza” lungo l’intera catena del valore, a cominciare dalla ricerca e dall’innovazione, e creare i giusti incentivi per accelerare l’adozione di soluzioni basate sull’IA, anche da parte delle piccole e medie imprese (PMI);
- gli elementi chiave di un futuro quadro normativo per l’IA in Europa, che creerà un “ecosistema di fiducia” unico. La costruzione di un ecosistema di fiducia è un obiettivo strategico in sé e dovrebbe dare ai cittadini la fiducia di adottare applicazioni di IA e alle imprese e alle organizzazioni pubbliche la certezza del diritto necessaria per innovare utilizzando l’IA.
La strategia europea per i dati che accompagna il “White Paper on AI” ha l’obiettivo di far sì che l’Europa diventi l’economia agile basata sui dati più attraente, sicura e dinamica del mondo, mettendo a sua disposizione i dati necessari a migliorare le decisioni e la vita di tutti i suoi cittadini.
Tale documento ha fatto emergere per l’European Union Agency for Cyber security (ENISA), la necessità di approfondire il tema della cyber security applicata all’IA, pubblicando nel dicembre 2020 il report “Artificial Intelligence Threat Landscape”.
I principali elementi del documento avanzato dall’ENISA sono i seguenti:
- Definizione dell’ambito dell’IA nel contesto della cyber security secondo un approccio basato sul ciclo di vita. Tenendo conto delle diverse fasi, dall’analisi dei requisiti all’implementazione, viene delineato l’ecosistema dei sistemi e delle applicazioni di IA.
- Identificazione degli asset dell’ecosistema IA come passaggio fondamentale per individuare ciò che deve essere protetto e cosa potrebbe eventualmente andare storto in termini di sicurezza dell’ecosistema IA.
- Mappatura del panorama delle minacce dell’IA mediante una tassonomia dettagliata. Ciò funge da base per l’identificazione di potenziali vulnerabilità ed eventualmente di scenari di attacco per casi d’uso specifici e servirà nelle valutazioni del rischio settoriale e nell’elenco dei controlli di sicurezza proporzionati.
- Classificazione delle minacce per i diversi asset e nel contesto delle diverse fasi del ciclo di vita dell’IA, elencando anche gli attori delle minacce rilevanti. Viene inoltre evidenziato l’impatto delle minacce su diverse proprietà di sicurezza.
Infine, nell’aprile 2021, la Commissione ha rilasciato la Revisione del Piano Coordinato sull’Intelligenza Artificiale che contiene una serie di azioni per rafforzare la posizione dell’UE nello sviluppo di sistemi AI che siano sostenibili, inclusivi, affidabili e che pongano l’uomo al centro del sistema IA. Tale piano propone da oggi al 2027 circa 70 azioni per una cooperazione più stretta ed efficiente tra gli Stati membri e la Commissione in tema di IA. Inoltre, la Commissione sosterrà i corsi di laurea magistrale e i dottorati di ricerca in IA proponendo una più stretta cooperazione tra i centri di eccellenza nella ricerca in materia di IA e, più in generale, i programmi di ricerca e innovazione dell’UE. Inoltre, sosterrà l’interdisciplinarità promuovendo lauree congiunte, ad esempio in legge o psicologia e IA. Le competenze digitali che facilitano lo sviluppo e l’uso dell’IA dovrebbero essere incluse in tutti i programmi di istruzione e formazione.
In Italia, come in altri paesi del panorama internazionale, il governo italiano ha pubblicato nel 2020 la bozza di Strategia nazionale per l’Intelligenza Artificiale. Più precisamente, viene sottolineato che l’IA presenta una forte interconnessione tra tre componenti:
- Ricerca e Trasferimento Tecnologico: la ricerca italiana in AI gode di una buona visibilità internazionale in alcuni settori specifici. Fanno parte dell’ecosistema le università ed i centri di ricerca pubblici/ privati nonché le reti di ricerca e di trasferimento tecnologico, come i Technology Cluster, i Competence Center, i Digital Innovation Hubs e i poli tecnologici regionali.
- Produzione: la produzione include l’industria del software, il comparto delle infrastrutture e dei servizi, l’industria della componentistica intelligente, dei semiconduttori per lo sviluppo di componenti IoT, automotive e telecomunicazioni, e il comparto dei sistemi e oggetti intelligenti, autonomi e semi autonomi, in particolare la robotica e l’automazione industriale.
- Adozione: l’adozione include la Pubblica Amministrazione (PA) e l’industria. La PA e le istituzioni possono utilizzare l’IA per la sicurezza, le città intelligenti, la sostenibilità ambientale, i trasporti, la gestione dei beni culturali e l’istruzione. Diversamente, nell’industria l’IA ha un utilizzo pervasivo che va dalla definizione di prodotto, marketing, logistica, pianificazione, fino ad arrivare alla manifattura.
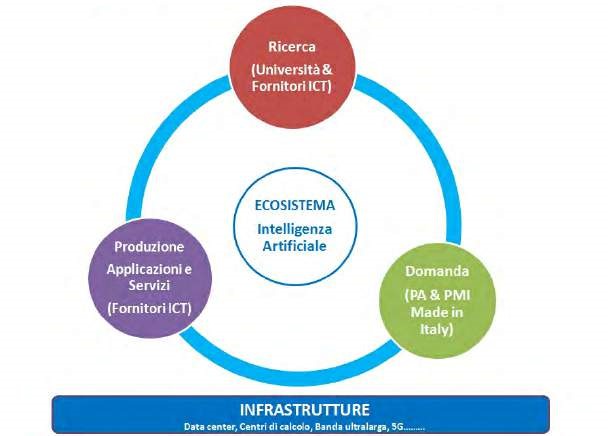
(fonte: Ministero dello Sviluppo Economico – Proposte per una strategia italiana per l’intelligenza artificiale, 2020)
L’intelligenza Artificiale e le misure di sicurezza
Secondo quanto indicato dall’articolo 5 dal Regolamento generale sulla protezione dei dati (GDPR) viene stabilita la sicurezza come principio nel trattamento dei dati personali. Più precisamente i dati personali devono essere trattati in maniera da garantire un’adeguata sicurezza dei dati personali, compresa la protezione, mediante misure tecniche e organizzative adeguate, da trattamenti non autorizzati o illeciti e dalla perdita, dalla distruzione o dal danno accidentali.
Questa caratteristica assume una significativa importanza per la sicurezza rispetto al passato, quando quest’ultima era una mera prestazione tecnico-organizzativa al di sopra dell’operazione di trattamento. Pertanto, è possibile affermare che nel GDPR la sicurezza è un prerequisito e la mancata adozione di adeguate misure di sicurezza invalida il trattamento e lo rende illecito. Analogamente agli altri principi di protezione dei dati, la sicurezza non è un’opzione ma una necessità.
In aggiunta, l’articolo 32 del GDPR prevede misure di sicurezza che devono essere ampliate in base al rischio di diversa probabilità e gravità per i diritti e le libertà degli interessati. Pertanto, il “bene” da tutelare con misure di sicurezza è il libero esercizio dei diritti delle persone, e non solo il bene informativo di per sé. I dati personali devono essere protetti in modo progressivo (maggiori sono i rischi, più rigorose sono le misure). La sicurezza è un modo per rafforzare i diritti e le libertà degli individui nel loro insieme e consente la centralità degli esseri umani rispetto alle macchine. I sistemi di IA sono sistemi logici e, in quanto tali, potrebbero non essere del tutto coerenti e completi, il che significa che gli esseri umani non saranno mai in grado di prevedere, in anticipo durante la fase di progettazione, tutti i possibili fattori contestuali che potrebbero comprometterne il funzionamento. Ciò espone le persone ai rischi intrinseci di esiti imprevisti in cui gli output di un sistema di IA non sono adeguatamente vincolati.
La sicurezza è anche uno strumento di protezione dei dati fin dalla progettazione, come previsto dall’art. 25 del GDPR. Tenendo conto di una serie di fattori contestuali (come lo stato dell’arte), i titolari del trattamento devono mettere in atto misure tecniche e organizzative adeguate. Tali misure devono essere in atto per attuare i principi di protezione dei dati in modo efficace, dalla minimizzazione all’accuratezza dei dati, integrando le necessarie salvaguardie nel trattamento. Nel dettaglio, il GDPR menziona specificamente la pseudonimizzazione come una di quelle misure efficaci. La dimensione della sicurezza per la protezione dei dati, nell’ambito dell’IA, è molto importante per poter introdurre le necessarie tutele tecniche e organizzative (per la tutela dei diritti e delle libertà delle persone) già nella fase di progettazione di nuove applicazioni di IA (security by design).
A tal fine, la sicurezza può anche essere un fattore abilitante di nuove operazioni di trattamento, in particolare legate alle tecnologie emergenti, come l’IA. Ad esempio, l’implementazione di misure di sicurezza specifiche, come la pseudonimizzazione o la crittografia, può portare i dati in un nuovo formato in modo che non possano essere attribuiti a un interessato specifico senza l’uso di dati informativi aggiuntivi (come una chiave di decrittazione). Queste opzioni potrebbero essere esplorate nel contesto dell’ambiente dell’IA, per modellare nuove relazioni tra umani e macchine, in modo che gli individui non siano per impostazione predefinita identificabili dalle macchine a meno che non lo desiderino. Ad esempio, una IA impostata allo scopo di annullare l’effetto della pseudonimizzazione o crittografia implementata.
Il legislatore europeo, ponendo la sicurezza tra i principi di protezione dei dati, stabilisce che questa è una condizione preliminare per il trattamento. Pertanto, la chiave è il passaggio dalla sicurezza come strumento difensivo alla sicurezza come elemento funzionale dell’ecosistema digitale. La sicurezza non deve essere implementata solo per prevenire perdite, ma anche per creare valore. Solo se le minacce alla sicurezza si affievoliranno, l’ecosistema AI può generare fiducia, attrarre investimenti, trattenere utenti e creare un feedback positivo per sviluppare ogni volta nuove applicazioni vantaggiose.
Il ciclo di vita dell’IA
Per inquadrare correttamente il dominio dell’IA, è essenziale seguire un approccio strutturato e metodico per comprenderne le diverse sfaccettature.
Il ciclo di vita di un sistema di Intelligenza Artificiale comprende diverse fasi interdipendenti che vanno dalla progettazione e sviluppo (comprese sottofasi come analisi dei requisiti, raccolta dati, formazione, test, integrazione), installazione, distribuzione, funzionamento, manutenzione e smaltimento. Data la complessità dei sistemi di Intelligenza Artificiale (e in generale delle informazioni), sono stati definiti diversi modelli e metodologie per gestire questa complessità, soprattutto durante le fasi di progettazione e sviluppo, come cascata, spirale, sviluppo software agile, prototipazione rapida e incrementale. Il ciclo di vita dell’IA definisce le fasi che un’organizzazione dovrebbe seguire per trarre vantaggio dalle tecniche di Intelligenza Artificiale e in particolare dai modelli di Machine Learning (ML) per ricavare valore di business pratico[1].
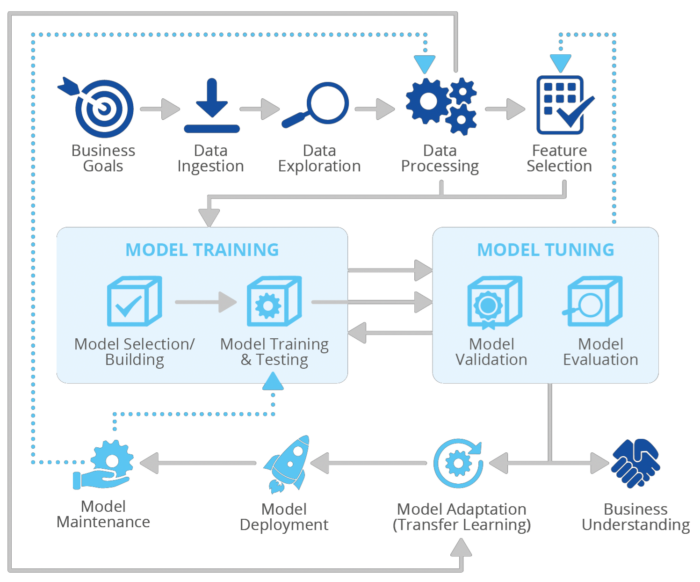
(fonte: ENISA – Artificial Intelligence Cybersecurity Challenges, 2020)
Business Goal Definition
In questa fase risulta di fondamentale importanza che l’organizzazione comprenda appieno il contesto aziendale dell’applicazione di intelligenza artificiale e i dati necessari per raggiungere i target prefissati.
Data Ingestion
Il Data Ingestion è la fase del ciclo di vita dell’IA in cui i dati vengono ottenuti da più fonti (i dati grezzi possono essere di qualsiasi forma strutturata o non strutturata). L’ acquisizione di dati è alla base di qualsiasi applicazione di intelligenza artificiale. I dati possono essere acquisiti direttamente dalle sue fonti in tempo reale, un modo continuo noto anche come streaming, o importando batch di dati, dove i dati vengono importati periodicamente in grandi macro-batch o in piccoli micro-batch.
Data Exploration
In questa fase le informazioni dettagliate iniziano a essere ricavate dai dati inseriti.
Data Pre-processing
La fase di preelaborazione dei dati utilizza tecniche per pulire, integrare e trasformare i dati. Questo processo mira a migliorare la qualità dei dati che migliorerà le prestazioni e l’efficienza dell’intero sistema di IA.
Feature Selection
Questa è la fase in cui viene ridotto il numero di componenti o caratteristiche (chiamate anche dimensioni) che compongono ciascun vettore di dati, identificando i componenti che si ritiene siano i più significativi per il modello di IA.
Model Selection / Building
Questa fase esegue la selezione/costruzione del miglior modello o algoritmo di intelligenza artificiale per l’analisi dei dati. Le tre categorie principali comunemente identificate sono l’apprendimento supervisionato, l’apprendimento non supervisionato e i modelli di apprendimento per rinforzo.
Model Training
Dopo aver selezionato un modello di IA, che nell’ambito di questo modello di riferimento fa per lo più riferimento a un modello di Machine Learning (ML), inizia la fase di training del sistema di IA.
Model Tuning
L’ottimizzazione del modello di solito si sovrappone all’addestramento del modello, poiché l’ottimizzazione è generalmente considerata all’interno del processo di addestramento.
Transfer Learning
In questa fase, l’organizzazione dell’utente utilizza un modello di intelligenza artificiale pre-addestrato e pre-sintonizzato e lo utilizza come punto di partenza per un’ulteriore formazione per ottenere una convergenza migliore e più rapida.
Model Deployment
Un modello di Machine Learning porterà conoscenza a un’organizzazione solo quando le sue previsioni saranno disponibili per gli utenti finali. La distribuzione è il processo in cui un modello viene reso disponibile agli utenti.
Model Maintenance
Dopo l’implementazione, i modelli di intelligenza artificiale devono essere continuamente monitorati e mantenuti per gestire le modifiche ai concetti e le potenziali derive concettuali che potrebbero verificarsi durante il loro funzionamento. La manutenzione del modello riflette anche la necessità di monitorare gli obiettivi e le risorse aziendali che potrebbero evolversi nel tempo e di conseguenza influenzare il modello stesso.
Business Understanding
In questa fase le aziende che implementano modelli di intelligenza artificiale acquisiscono informazioni sull’impatto dell’IA sul proprio business e cercano di massimizzare le probabilità di successo.
Attori del ciclo di vita dell’IA
Nella rosa delle figure coinvolte nell’ecosistema dell’IA vi sono numerosi attori attivamente coinvolti.
In primo luogo, è possibile ricordare i progettisti di intelligenza artificiale impegnati nella progettazione e creazione di sistemi di intelligenza artificiale. Successivamente, vi sono gli sviluppatori di intelligenza artificiale con il compito di costruire e sviluppare il software e gli algoritmi utilizzati nei sistemi di intelligenza artificiale, oltre a lavorare per perfezionarli e migliorarli. Queste ultime figure collaborano con i cosiddetti data scientist, i quali sono coinvolti nella raccolta e nell’interpretazione dei dati, concentrandosi sull’estrazione di conoscenze e approfondimenti da tali dati. Inoltre, sono presenti anche i data engineers i quali prestano particolare attenzione alla progettazione, gestione e ottimizzazione del flusso di dati.
Un altro attore che ricopre un’importanza significativa nel ciclo di vita dell’IA è il data owner il quale possiede i set di dati utilizzati per addestrare o convalidare i sistemi di intelligenza artificiale. Diversamente, i model providers che forniscono modelli (nonché implementazioni di essi sotto forma di librerie IA/ML) che sono già stati formati e messi a punto. Alcuni model providers sono dei cloud providers, ed offrono i modelli come servizio, in particolare l’uso di capacità di calcolo e analisi dei dati basate sull’intelligenza artificiale nel cloud.
Infine, vi sono gli utenti finali che utilizzano i sistemi di intelligenza artificiale. Tra questi è possibile menzionare i consumatori di servizi, ma anche il pubblico in generale.
Cybersecurity threats: minacce dell’IA
Come già sottolineato, l’intelligenza artificiale consente il processo decisionale automatizzato e facilita molti aspetti della vita quotidiana, portando con sé miglioramenti delle operazioni e numerosi altri vantaggi. Tuttavia, i sistemi di IA devono far fronte a numerose cybersecurity threats. Pertanto, è necessario analizzare i vari gruppi di attori coinvolti nelle minacce e successivamente approfondire la tassonomia delle minacce nell’ecosistema dell’IA.
Attori minacciatori
Le figure che potrebbero voler danneggiare i sistemi di IA utilizzando mezzi informatici sono i seguenti:
- Cyber criminali: essi sono motivati principalmente dal profitto e tendono ad utilizzare l’IA come strumento per condurre attacchi, ma anche per sfruttare le vulnerabilità nei sistemi di IA esistenti.
- Insider: essi sono figure interne ad un’azienda ed hanno accesso alle reti di un’organizzazione, possono coinvolgere coloro che hanno intenzioni dannose o coloro che possono danneggiare un’azienda involontariamente.
- Nation state actors: questi soggetti sono principalmente sponsorizzati dagli stati sia per difendere le proprie reti, ma anche per sfruttare le vulnerabilità dei sistemi di intelligenza artificiale di altri paesi
- Terrorists: sono figure che hanno l’obiettivo di causare chiaramente dei danni fisici o di danneggiare la sicurezza nazionale di un paese.
- Hacktivists: essi sono un gruppo di hacker, motivati ideologicamente, che possono hackerare i sistemi di intelligenza artificiale per dimostrare le vulnerabilità di infrastrutture critiche.
- Script Kiddies: essi sono generalmente un gruppo di individui non qualificati che utilizzano script o programmi pre-scritti per attaccare i sistemi di IA.
Tassonomia delle minacce
È possibile utilizzare una tassonomia delle minacce per mappare il panorama delle minacce nell’ecosistema dell’Intelligenza Artificiale.
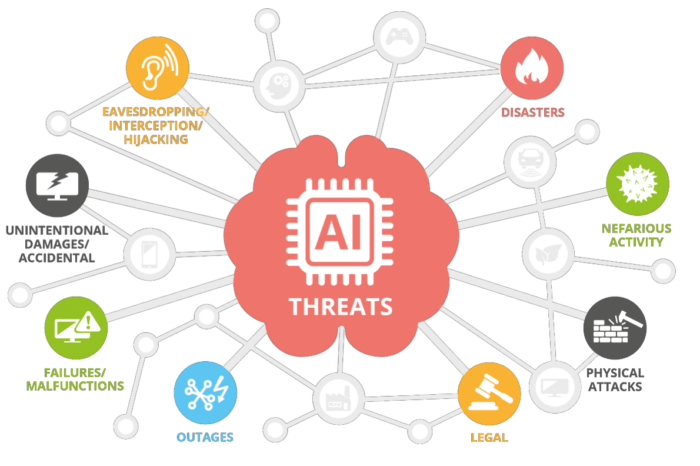
(fonte: ENISA – Artificial Intelligence Cybersecurity Challenges, 2020)
- Nefarious activity/abuse (NAA): sono le azioni previste che prendono di mira i sistemi ICT, infrastrutture e reti mediante atti dannosi con l’obiettivo di rubare, alterare o distruggere un determinato obiettivo.
- Eavesdropping/ Interception/ Hijacking (EIH): sono le azioni volte ad ascoltare, interrompere o prendere il controllo di una comunicazione di terzi senza consenso.
- Physical attacks (PA): sono le azioni che mirano a distruggere, esporre, alterare, disabilitare, rubare o ottenere l’accesso non autorizzato a risorse fisiche come infrastrutture, hardware o interconnessione.
- Unintentional Damage (UD): sono le azioni non intenzionali che causano distruzione, danno o lesione di cose o persone e si traducono in un fallimento o riduzione dell’utilità.
- Failures or malfunctions (FM): sono le azioni che causano un insufficiente o parziale funzionamento di un bene (hardware o software).
- Outages (OUT): sono le azioni che causano interruzioni impreviste del servizio o diminuzione della qualità al di sotto un livello richiesto.
- Disaster (DIS): sono le azioni che causano un incidente improvviso o una catastrofe naturale che provoca gravi danni o perdita di vite umane.
- Legal (LEG): sono le azioni legali di terzi, contrattuali e non contrattuali, al fine di vietare azioni o compensare perdite in base alla legge applicabile.
Conclusioni
La significativa importanza che ricopre l’Intelligenza Artificiale nella società odierna non può essere certamente trascurata. Essendo agli albori di una nuova rivoluzione digitale, è stato stimato che il mercato globale dell’intelligenza artificiale nell’arco temporale 2020-2027 possa crescere con tasso medio annuo del 42.2%.
Pertanto, è doveroso sottolineare come qualsiasi ambito della nostra vita sia sotto l’aspetto quotidiano, economico, professionale e del lavoro subirà un cambiamento, così dando origine ad una convivenza tra uomo e digitale.
Come osservato dallo storico Y.N. Harari[2], l’Intelligenza Artificiale realizza due capacità particolarmente importanti che sono la connettività e la possibilità di aggiornamento. “Poiché gli esseri umani sono individui, è difficile connetterli l’uno all’altro e assicurarsi che siano tutti aggiornati. Le macchine invece non sono individui ed è facile integrarle in una singola rete flessibile. Pertanto, non si tratta di sostituzione di milioni di lavoratori individuali con milioni di individui robot e computer. È più verosimile che gli individui umani siano rimpiazzati da una rete integrata”.
Note
[1] ENISA, Artificial Intelligence Cybersecurity Challenges, Dicembre 2020.
[2] Y.N. Harari, 21 lezioni per il XXI secolo, Bompiani, 2018.
Articolo a cura di Luca Barbieri

Luca Barbieri è laureato in Giurisprudenza presso l’Università Luiss Guido Carli con tesi intitolata “From cyber espionage to cyber warfare: a criminal comparative analysis between Italy, USA and China”, nella materia di Diritto Penale, con il Relatore Prof. Gullo.
Durante l’Exchange Program, presso la Beijing Normal University di Pechino, ha sostenuto esami di diritto cinese e cyber security.
Inoltre, ha conseguito il corso “Big data, artificial intelligence e piattaforme: aspetti tecnici e giuridici connessi all'utilizzo dei dati e alla loro tutela” presso l’Università degli Studi di Milano ed il Master universitario di secondo Livello in “Responsabile della protezione dei dati personali: Data Protection Officer e Privacy Expert” presso l’Università Roma Tre, con tesi intitolata “Cybersecurity: sistemi di Intelligenza artificiale a protezione delle reti e delle infrastrutture critiche”, con il Relatore Prof. Avv. Aterno.
Attualmente è Dottorando in “Security, Risk and Vulnerability” presso l’Università di Genova e collabora in uno studio legale specializzato in cybersecurity e data protection fornendo assistenza nelle attività di compliance alla Direttiva NIS, al Perimetro di Sicurezza Nazionale Cibernetica ed al GDPR.





