

Modello di autovalutazione relativo a un sistema di Intelligenza Artificiale
Introduzione
L’intelligenza artificiale – o meglio, i devices che posseggono una qualche forma di intelligenza artificiale – sono ormai numerosi. Sono innumerevoli le applicazioni che utilizzano la AI per analizzare, confrontare i dati e produrre risultati. L’intelligenza artificiale (IA), la robotica, i dati e il machine learning entrano quotidianamente nelle nostre case, nei luoghi di lavoro e nell’ecosistema sociale.
È opportuno anche definire cosa si intenda per Intelligenza Artificiale. Quando si parla di AI si pensa subito ai robot, a tecnologie di avanguardia, a un mondo futuristico con sistemi complessi utilizzati in moltissimi settori. Si tratta però anche di sistemi meno invasivi e meno visibili: si pensi al machine learning, ai big data o alle reti neurali.
In pratica l’Intelligenza Artificiale è un ramo dell’informatica che permette la programmazione e la progettazione di sistemi sia hardware che software, conformando le macchine a determinate caratteristiche tipicamente umane (il tatto, le percezioni visive, le percezioni spazio-temporali, le prese decisionali).
I dati sono i mattoni dell’IA; a volte sono semplici algoritmi, ma spesso sono esponenzialmente più complessi.
L’aumento delle tecnologie digitali, insieme all’enorme quantità di dati prodotti ogni giorno da ognuno di noi, ha dato all’intelligenza artificiale una dimensione interamente nuova e importante: il machine learning, un’applicazione dell’IA che offre ai sistemi la capacità di imparare automaticamente e migliorare dall’esperienza senza essere esplicitamente programmati.
Il machine learning si concentra sullo sviluppo dei software per computer che possono accedere ai dati e usarli per imparare in autonomia.
Si considera, quindi, non solo l’intelligenza intesa come capacità di calcolo o conoscenza di dati astratti, ma anche di forme di intelligenza riconosciute dalla teoria di Gardner e che possono considerare l’intelligenza spaziale, sociale, cinestetica o introspettiva. Un sistema intelligente viene realizzato cercando di ricreare una o più di queste differenti forme che, anche se considerate come semplicemente umane, possono essere ricondotte a particolari comportamenti riproducibili da alcune macchine.
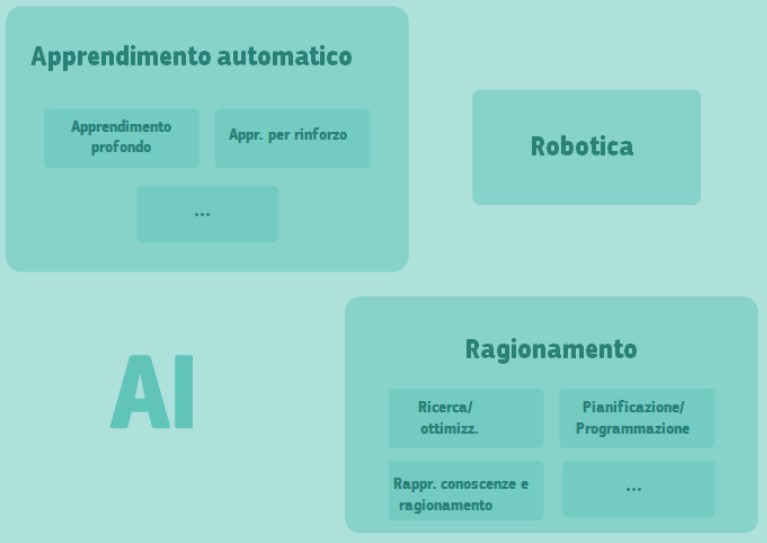
Immagine del report: “Una definizione di IA: principali capacità e discipline scientifiche Gruppo di esperti ad alto livello sull’intelligenza artificiale della Commissione Europea (aprile 2019), Figura 2: quadro semplificato delle sottodiscipline dell’IA e delle correlazioni esistenti tra di esse”
Per un efficace sistema di gestione dell’AI è necessario definire alcuni principi, sia dal punto di vista etico sia dal punto di vista della sicurezza e dell’impatto sull’utente.
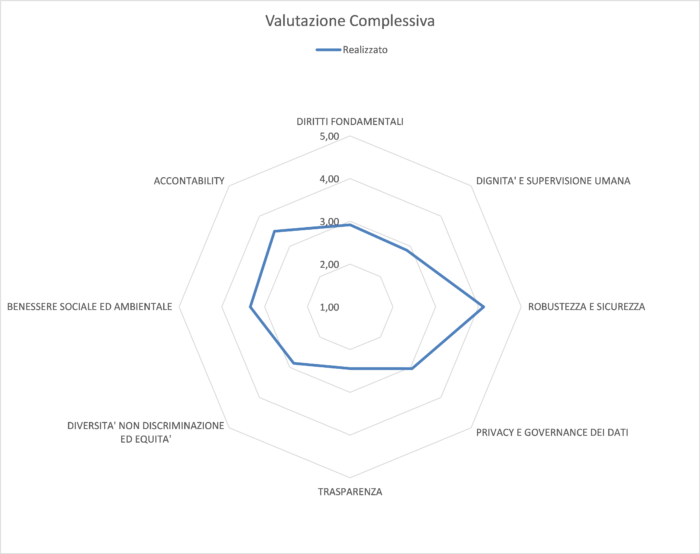
I principi – dignità e supervisione umana; robustezza e sicurezza; privacy e governance dei dati; trasparenza; diversità, non discriminazione ed equità; benessere sociale e ambientale; accountability – vanno poi declinati in ulteriori controlli.
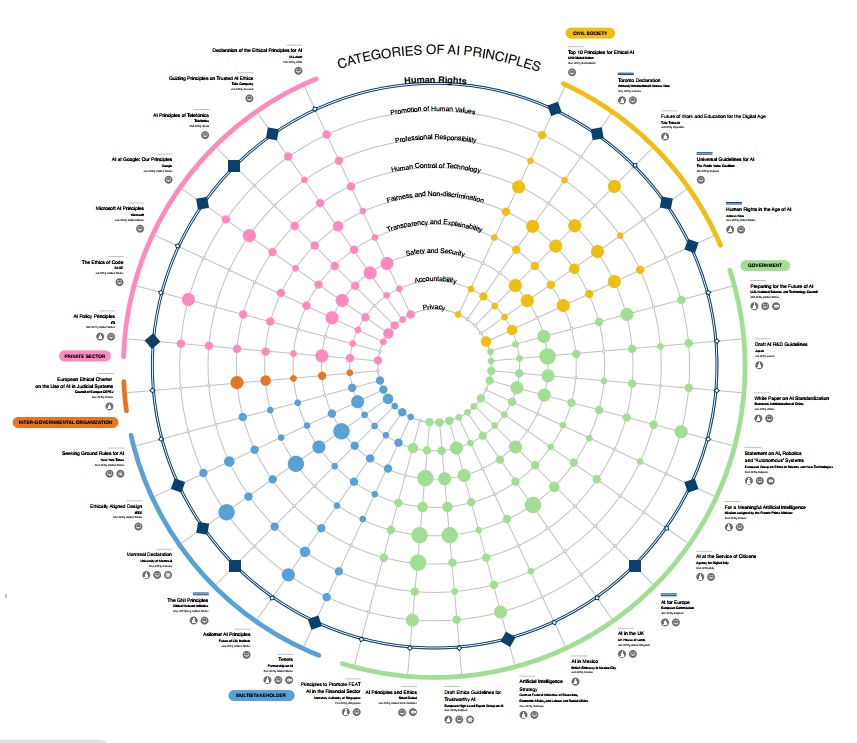
Fonte: Research Publication No. 2020 -1 January 15, 2020 Principled Artificial Intelligence: Mapping Consensus in Ethical and Rights-based Approaches to Principles for AI
Risulta quindi fondamentale avere un approccio olistico di governance, che va oltre la componente tecnologica per abbracciare varie discipline tra loro correlate (tecniche, giuridiche, tecnologiche, di GRC [governance, risk, compliance]) affrontando l’argomento in termini di metodologia.
Metodologia
Il sistema di autovalutazione illustrato è stato mutuato dal framework del CSF e CSFP del NIST, nonché dalla linea guida Assessment List for Trustworthy AI (ALTAI) del luglio 2020.
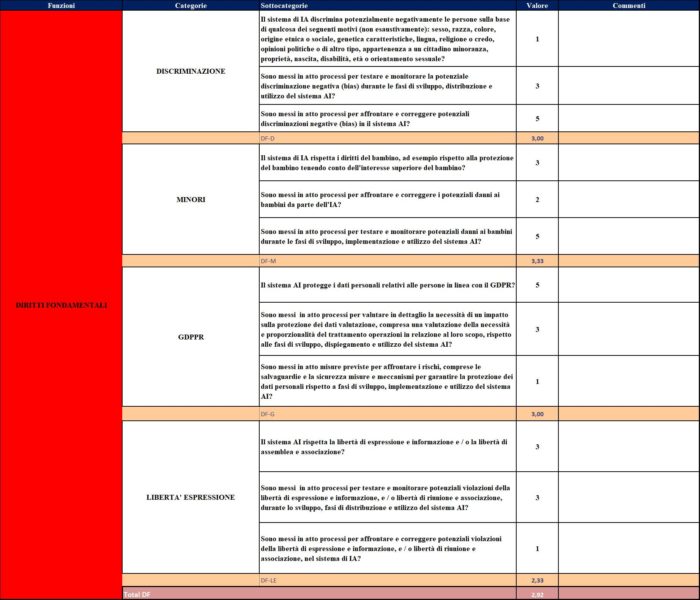
Il tool utilizza le sette categorie dell’AI e utilizzando un modello simile ai framework riportandole nelle funzioni del modello; vengono poi individuate delle categorie dedicate e delle sotto categorie che corrispondono alle domande dell’autovalutazione.
Viene introdotta anche una scala di maturità (1, 3 e 5) come punteggio da assegnare alle singole risposte delle sotto categorie. La scala riporta il valore di completezza delle risposte.
Il modello produce poi dei grafici riassuntivi della fotografia dell’organizzazione. Riportiamo un esempio del modello.


È opportuno anche porsi alcune rapide domande in merito alla sicurezza e ai rischi relativi all’implementazione di un sistema AI, che ci permettono di comprendere meglio cosa e come fare e rendere più efficace l’autovalutazione:
- determinare il contesto di sicurezza nazionale;
- identificare il tipo di applicazione AI utilizzata;
- identificare i potenziali rischi e i problemi associati all’applicazione;
- determinare le metriche più importanti che potrebbero aiutare a indicare che il sistema “lavora” in modo affidabile, accurato, appropriato;
- scegliere un tipo di standard e adattalo alle metriche precedentemente identificate;
- identificare le considerazioni, le limitazioni e i presupposti chiave.
Nel quadro dell’approccio olistico sopra delineato, va sempre tenuto a mente che l’impatto delle intelligenze artificiali nella dimensione reale passa attraverso due principali macro-argomenti: l’etica e la responsabilità.
Da una parte, dunque, è bene riferirsi alle Linee Guida Etiche sull’intelligenza artificiale[1] della Commissione Europea, caratterizzate da un approccio umano-centrico, e che rivolgono il focus su alcuni principi etici e argomenti quali la sicurezza, la riservatezza e la privacy dei dati e del materiale informatico in questo particolare ambito.
Per essere eticamente corretta l’AI deve essere sostanzialmente affidabile, il che si traduce concretamente in conformità alle leggi, rispetto dei principi etici e solidità, ossia principi capaci di assicurare la centralità della dignità e delle libertà umane.
Inoltre – ci ricordano le Linee Guida – va tenuto in buon conto che 7 sono i requisiti individuati, come anche riportato sopra e qui integrati, affinchè un’intelligenza artificiale possa dirsi anche etica, ossia è necessario che vi siano:
- supervisione umana e dunque che i sistemi di IA siano sorvegliati da personale umano, a garanzia del rispetto dei diritti fondamentali e del benessere dell’utente;
- robustezza e sicurezza, intese come sicurezza ed affidabilità degli algoritmi e come tenuta dei sistemi di controllo in caso di ipotetiche operazioni illecite;
- privacy, controllo e gestione dei dati;
- trasparenza a garanzia della tracciabilità dei sistemi e a dimostrazione delle operazioni compiute dell’algoritmo;
- diversità, correttezza, assenza di discriminazione: i sistemi di intelligenza artificiale dovrebbero tenere conto delle diverse e distinte abilità e capacità umane, garantendo al tempo stesso a tutti il libero accesso a tali strumenti;
- benessere sociale e ambientale, ossia avere sempre riguardo all’impatto sull’ambiente e sull’assetto sociale, promuovendo l’utilizzo dell’IA solo laddove il suo utilizzo possa garantire uno sviluppo sostenibile;
- responsabilità, ovvero verifica continua dei sistemi, sia internamente che esternamente.
Riprendendo l’ancor attualissimo pensiero del Prof. Rodotà, insomma, “proprio perché i problemi più acuti nascono dalla disponibilità di un arsenale tecnologico sempre più imponente, qui come altrove bisogna chiedersi se tutto quel che è tecnicamente possibile sia pure eticamente lecito, politicamente e socialmente accettabile, giuridicamente ammissibile. L’avvenire democratico si gioca sempre di più intorno alla capacità sociale e politica di trasformare le tecnologie dell’informazione e della comunicazione in tecnologie della libertà, e non del controllo”.
Altro aspetto che va debitamente soppesato in una valutazione a tutto tondo è quello inerente i profili di responsabilità che potrebbero derivare in caso di errore durante l’utilizzo dell’intelligenza artificiale (e quindi il problema dell’attribuzione della responsabilità) e di risarcimento dell’eventuale danno.
Oltre ai rischi prettamente materiali, sono da valutare anche quelli informatici, legati al software, all’algoritmo (e alla mancanza di trasparenza dello stesso), ai comandi a distanza, alla cybersicurezza e ai cyber-attacchi, alla manutenzione, alla messa in sicurezza dei dati personali e delle informazioni, così come le ricadute in ambito di danni e di titolarità delle responsabilità.
Ecco che, quindi, ancora una volta bisognerà seguire il principio del Risk Based Approach, adottando modelli di “security by design” e “by default” che permettano di improntare i processi al rispetto dei principi in materia di privacy e sicurezza, come del controllo, aggiornamento e adeguamento periodico e sistematico di dati e informazioni.
Sul punto, un profilo particolarmente dibattuto da ultimo è quello relativo alla possibilità di aprire la strada a una responsabilità civile per danno da algoritmo (forse anche mediante la creazione di una personalità giuridica ad hoc per l’AI), quanto meno nei casi di algoritmi generati da machine learning o deep learning, caratterizzati – oltre che dai tre elementi tipici dell’AI (interattività, autonomia, adattabilità) – anche dall’imprevedibilità[2].
In tal senso, essendo l’AI costituita da sistemi complessi, bisognerebbe capire se incardinare la responsabilità sulla figura del solo produttore dell’AI – ad esempio –, o se configurarla in capo a ulteriori e diversi responsabili, partendo da chi ne abbia realizzato una singola parte sino ad arrivare – in via potenziale – direttamente all’algoritmo di base del sistema.
Ulteriore punto discusso è quello relativo ai casi di danni prodotti direttamente dall’AI in qualità di soggetto agente: in questa evenienza secondo alcuni si potrebbe tranquillamente riconoscere una responsabilità anche penale in capo all’AI, mentre secondo la tesi avversaria, non potendo essere rintracciati gli elementi di base di una vera e propria responsabilità, l’AI non potrebbe rispondere di alcunchè e – ovviamente – neppure essere sanzionata.
Di certo, come si legge nel White Paper del 19 febbraio 2020 della Commissione Europea[3], “gli attori economici rimangono pienamente responsabili di garantire che l’IA sia conforme alle attuali norme sulla protezione dei consumatori. Qualsiasi sfruttamento algoritmico del comportamento del consumatore in violazione delle disposizioni esistenti è proibito e le violazioni saranno sanzionate di conseguenza”.
Ecco che quindi, attraverso un’azione legislativa comune, l’Unione Europea (e l’Italia nel suo piccolo) avrebbero tutto il potenziale necessario per diventare un modello di riferimento e riuscire a trovare la risposta ad alcune domande che naturalmente scaturiscono dall’utilizzo dell’intelligenza artificiale.
In quest’ottica, dunque, è bene non dimenticare di guardare anche agli ultimi lavori in tema condotti dal Servizio di Ricerca del Parlamento Europeo (European framework on ethical aspects of artificial intelligence, robotics and related technologies[4]) e dal MISE (Strategia Nazionale per l’Intelligenza Artificiale[5]).
L’EPRS ci ricorda, infatti, che dall’uso dell’intelligenza artificiale possono derivare grandi vantaggi per i cittadini, le imprese e i pubblici servizi (ad es. migliore assistenza sanitaria, automobili e altri sistemi di trasporto più sicuri e anche prodotti e servizi su misura, più economici e più resistenti), ma anche rischi rilevanti (abuso e sottoutilizzo, responsabilità civile, minacce ai diritti fondamentali e alla democrazia, scomparsa di posti di lavoro).
Nello specifico e sugli aspetti di responsabilità per danni causati da un dispositivo o servizio azionato dall’intelligenza artificiale, nella Relazione ci si interroga su chi sarebbe tenuto a pagare i danni in caso di incidente con un’auto a guida autonoma: il proprietario, il costruttore o il programmatore?
Se il produttore fosse privo di responsabilità potrebbero non esserci incentivi sufficienti a fornire un prodotto sicuro ed efficiente e il pubblico potrebbe finire per avere meno fiducia nella tecnologia. Ma, allo stesso tempo, anche norme troppo severe potrebbero soffocare i tentativi di innovazione.
La strategia italiana sull’intelligenza artificiale sembra allinearsi a quella europea, nell’ottica di un’AI “affidabile”, che sappia conquistare la fiducia dei cittadini grazie a caratteristiche come trasparenza, robustezza, resilienza, antropocentrismo e miglioramento della vita delle persone.
“L’IA deve essere al servizio delle persone, garantendo una supervisione umana, prevenendo i rischi di inasprimento degli squilibri sociali e territoriali potenzialmente derivanti da un suo utilizzo inconsapevole o inappropriato. L’IA deve essere progettata e realizzata in modo affidabile e trasparente, per una sua accettabilità consapevole e una intrinseca robustezza affinché sia adottabile in ogni ambito produttivo e capace di rispondere alle sfide sociali del nostro Paese. L’IA deve generare opportunità di crescita e di benessere per tutti gli individui, in linea con i principi contenuti nell’articolo 3 della Costituzione italiana e gli Obiettivi di Sviluppo Sostenibile delle Nazioni Unite (ONU). Deve essere essa stessa una tecnologia sostenibile e fornire strumento per la sostenibilità ambientale, economica e sociale”.
E ancora, “I dati sono il carburante delle tecnologie IA. E sono i dati ad aver ‘cambiato le carte’ in tavola. È stata, infatti, la disponibilità di informazioni in formato digitale, più ancora che l’aumentata capacità di calcolo, a spiegare lo sviluppo dell’IA nell’ultimo decennio. Dati strutturati e non, attività su Internet, sensori che rilevano dati in qualsiasi ambiente: dalla strada all’industria. Se è qui il fulcro dello sviluppo dell’IA, dobbiamo continuare a focalizzare la nostra attenzione su questo aspetto, gestendolo anziché lasciare che altri lo facciano per noi.
In questo senso l’impegno italiano è definire una policy dei dati”.
Cruciale, quindi, è la sicurezza dei dati. In questo senso l’attuazione della direttiva NIS è stato il primo passo; il secondo sarà l’attuazione della legge sul perimetro di sicurezza nazionale cibernetica.
C’è da augurarsi che sarà il più importante cambio di paradigma tecnologico dei nostri tempi.
Note
[1] https://www.europarl.europa.eu/RegData/etudes/BRIE/2019/640163/EPRS_BRI(2019)640163_EN.pdf
[2] Sul punto si vedano anche: M. D’Agostino Panebianco, “Legal aspects and liability of Algorithm, in the light of the White Paper on AI of European Commission”, https://www.federalismi.it/nv14/articolo-documento.cfm?Artid=44090&content=Legal%2Baspects%2Band%2Bliability%2Bof%2BAlgorithm%2C%2Bin%2Bthe%2Blight%2Bof%2Bthe%2BWhite%2BPaper%2Bon%2BAI%2Bof%2BEuropean%2BCommission&content_author=%3Cb%3EManlio%2Bd%27Agostino%2BPanebianco%3C%2Fb%3E e Anna Capoluongo, “AI, la giurisprudenza guarda al danno da algoritmo”, https://www.ai4business.it/intelligenza-artificiale/ai-la-giurisprudenza-guarda-al-danno-da-algoritmo/#post-5361-footnote-5
[3] https://ec.europa.eu/info/publications/white-paper-artificial-intelligence-european-approach-excellence-and-trust_en
[4] https://www.europarl.europa.eu/RegData/etudes/STUD/2020/654179/EPRS_STU(2020)654179_EN.pdf
[5] https://www.mise.gov.it/images/stories/documenti/Strategia_Nazionale_AI_2020.pdf
Articolo a cura di Stefano Gorla, Anna Capoluongo e Augusto Bernardi

Consulente e formatore in ambito governance AI, sicurezza e tutela dei dati e delle informazioni;
Membro commissione 533 UNINFO su AI; Comitato di Presidenza E.N.I.A.
Membro del Gruppo di Lavoro interassociativo sull’Intelligenza Artificiale di Assintel
Auditor certificato Aicq/Sicev ISO 42001, 27001, 9001, 22301, 20000-1, certificato ITILv4 e COBIT 5 ISACA, DPO Certificato Aicq/Sicev e FAC certifica, Certificato NIST Specialist FAC certifica,
Referente di schema Auditor ISO 42001 AicqSICEV.
Master EQFM. È autore di varie pubblicazioni sui temi di cui si occupa.
Relatore in numerosi convegni.

Avvocato Data Protection & ICT | Data Protection Officer UNI 11697 | membro dell’EDPB’s Support Pool of Experts | Membro Women For Security | Membro Osservatorio sulla Giustizia Civile Tribunale Milano (Gruppo sul danno da illecito trattamento dei dati personali) | Afferente B-ASC (Università Milano-Bicocca Applied Statistics Center) | Vicepresidente Institute for Research of Law Economical and Social Studies| Membro Gruppo di Lavoro sull’AI di ANORC | Docente a c. (Università di Padova, Sole24Ore Business School), Comitato di Presidenza E.N.I.A.

Augusto Bernardi, nato a Bressanone (BZ), ha seguito un ciclo di studi in giurisprudenza e diritto internazionale presso l’Università di Innsbruck (A). Dopo un'esperienza nel modo assicurativo e finanziario si è dedicato alla consulenza normativa, giuridica e di protezione dei dati delle cooperative di distribuzione elettrica e centrali di teleriscaldamento della Provincia di Bolzano.
Negli ultimi anni si è dedicato all’approfondimento delle conoscenze della nuova regolamentazione europea in materia di protezione dei dati e opera come consulente privacy e responsabile per la protezione dei dati per numerose aziende dell’Alto Adige.
Formatore e relatore in ambito sicurezza e tutela dei dati per le aziende e organizzazioni pubbliche, è DPO Certificato UNI 11697 da FAC Certifica.





