

Sorveglianza e profitto: qual è il giusto prezzo di ciò che è gratuito?
“E la Yakuza stava stendendo la sua rete occulta sulle banche dati della città, cercando pallide immagini di me stesso riflesse su numeri di conto corrente, assicurazioni, bollette. Siamo un’economia fondata sull’informazione. Lo insegnano a scuola. Quello che non dicono è che è impossibile muoversi, vivere, operare a qualunque livello senza lasciare tracce, segni, frammenti di informazione apparentemente privi di significato. Frammenti che possono essere recuperati e amplificati…”
William Gibson, “Johnny Mnemonic”, 1981
Lo scandalo Facebook-Cambridge Analytica e la sorveglianza digitale
A metà 2014 Cambridge Analytica (azienda che accumula dati personali per creare profili psicologici per campagne di comunicazione e che opera secondo un sistema di microtargeting[1] comportamentale) commissionò a Aleksander Kogan, docente di psicologia all’università di Cambridge, la raccolta di alcune informazioni relative a profili di utenti Facebook. Kogan creò l’app “This is your digital life”, essenzialmente un quiz sulla personalità, riuscendo a somministrarlo anche tramite l’utilizzo di piattaforme quali Mechanical Turk di Amazon, uno dei servizi più controversi della cosiddetta gig economy[2] il cui motto recita “Intelligenza Umana tramite API – Accesso a una forza lavoro globale, su richiesta e 24×7”.
Kogan riuscì a far eseguire il quiz a poco meno di 300.000 utenti Facebook (dietro pagamento di pochi centesimi a ciascuno di essi) e a raccogliere informazioni non solamente su di loro, ma anche sui loro amici (nel caso in cui i settaggi della privacy lo consentissero), ampliando il perimetro di collezione dei dati ad un numero di utenti sconosciuto ma oscillante tra 50 e 90 milioni.
Kogan, in realtà, prima di sviluppare la propria app cercò invano di convincere Michal Kosinski, uno dei principali studiosi dell’intersezione tra psicometria[3] e big data, a fargli utilizzare i dati raccolti tramite analoghe app che quest’ultimo aveva realizzato per scopi di ricerca. Kosinski aveva dimostrato nel 2013 la possibilità di predire tratti e attributi personali da una varietà di informazioni che generiamo quotidianamente durante l’utilizzo delle piattaforme di social network o di altri servizi Web: ad esempio, analizzando i Like su Facebook è possibile dedure con buona accuratezza diverse informazioni personali[4]. Kosinski si è sempre detto preoccupato per l’elevato rischio di perdita della privacy connaturato a pratiche sconsiderate di raccolta e analisi dei dati.
Normalmente Facebook ha sempre consentito agli sviluppatori che realizzano app all’interno del proprio ecosistema questo genere di raccolta dei dati, ma solamente per scopi di ricerca accademica e non per utilizzo commerciale. Facebook accusa Kogan di aver venduto i dati ricavati tramite la propria app a Cambridge Analytica, violando le regole e le policy aziendali. Facebook ha anche sospeso improvvisamente Cambridge Analytica dalla propria piattaforma: a quanto pare sapeva del problema da un paio d’anni ma non era stato realizzato alcun intervento risolutivo, come sostenuto dall’immancabile whistleblower (ce n’è sempre uno in ogni scandalo che si rispetti) Christopher Wylie, ex dipendente di Cambridge Analytica.
Non siamo quindi in presenza di alcuna violazione di sicurezza o Data Breach, ma di un utilizzo dei dati considerato illegittimo da parte di Facebook.
Microtargeting, sorveglianza e utilizzo dei dati da parte delle aziende
Non solo Facebook, anche Google. Microsoft, Amazon, Alibaba e tante altre aziende fanno business tramite la condivisione e la compravendita di profili digitali. Molti aspetti relativi alla personalità possono essere dedotti dalle ricerche che effettuiamo quotidianamente sul web, dall’history del nostro browser, da come guardiamo i video, dalle attività che facciamo sui social network e dagli acquisti che operiamo. Attributi personali sensibili quali etnia, appartenenza religiosa o politica, stato civile, orientamento sessuale, utilizzo di droghe, alcool o sigarette possono essere ricavate dai Like di Facebook. Stessi risultati sono ottenibili tramite l’analisi delle app e del traffico telefonico così come dagli schemi di digitazione sulla tastiera[5]:
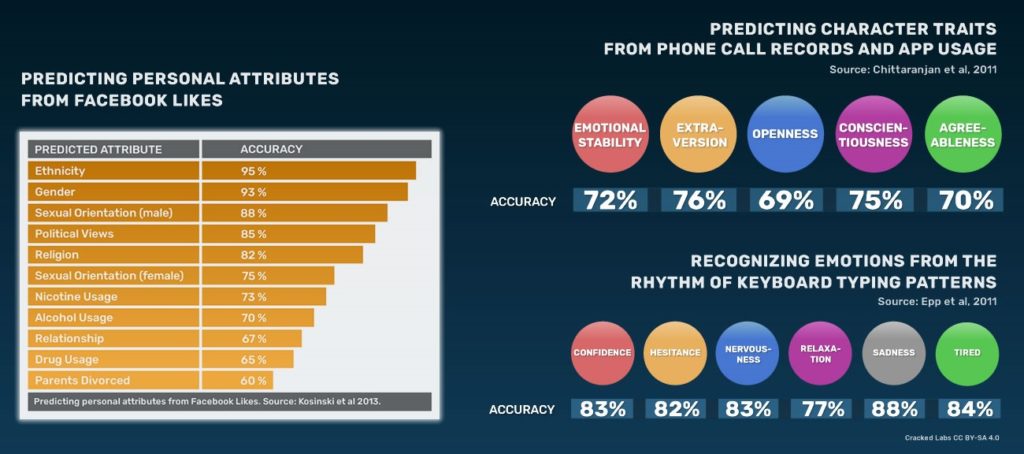
I metodi attuali di data mining e analytics poggiano su correlazioni statistiche con determinati livelli di probabilità e nonostante il miglioramento generalizzato delle capacità predittive degli algoritmi ci sono ancora margini di miglioramento in termini di accuratezza. Questi metodi sono utilizzati per ordinare, categorizzare, etichettare, sistemare, valutare e classificare le persone non solo per finalità di marketing, ma anche in contesti decisionali quali le operazioni finanziarie, assicurative, sanitarie o per influenzare scenari politici. Alcuni use case tipici riguardano la valutazione del merito di credito tramite dati di comportamento digitale o la previsione sulla salute in base ai dati dei consumatori.
Data broker e sorveglianza dei consumatori: il nuovo capitalismo
La raccolta dei dati personali digitali avviene su scala globale: Facebook detiene i profili digitali di circa 2 miliardi di utenti della propria piattaforma, oltre a quelli di Whatsapp e Instagram.
Google ha i profili di oltre 2 miliardi di utenti di dispositivi Android, oltre a quelli di Gmail e Youtube. Apple possiede i profili di circa 1 miliardo di proprietari di dispositivi con a bordo iOS. I profili digitali di Facebook usano circa 52.000 attributi per identificare l’identità dei propri utenti e categorizzarli: tutto ciò è possibile tramite l’analisi di post, Like, commenti, condivisioni, amici, foto, video, check-in di localizzazione geografica e così via. Cosa di notevole interesse, sono aziende come Facebook a comprare altra informazione da broker di dati come Acxiom per aumentare il perimetro di analisi e migliorare l’accuratezza dei propri profili digitali.
I broker di dati sono al centro dell’industria dei dati personali e si occupano di aggregare, combinare e scambiare commercialmente enormi quantità di informazioni, collezionate da sorgenti disparate sia online sia offline. Di solito i dati provengono da fonti diverse dagli individui e spesso, soprattutto nel cyberspazio, sono collezionati senza consenso. I broker analizzano i dati, fanno deduzioni e applicano inferenze, ordinano i profili in categorie e forniscono migliaia di attributi individuali ai propri clienti.
I profili che i broker hanno sugli individui includono informazioni relative a educazione, lavoro, figli, religione, etnia, schieramento politico, attività, interessi, utilizzo dei media, ma anche comportamenti online quali, ad esempio, le ricerche effettuate sul web. I broker collezionano dati relativi agli acquisti, all’utilizzo delle carte di credito, al reddito e ai prestiti, alle posizioni bancarie e assicurative, alla proprietà di veicoli e immobili e a una varietà di altre tipologie di dato. I broker calcolano punteggi in grado di predire il possibile comportamento futuro di un individuo, con attenzione, ad esempio, alla stabilità economica o ai piani di fare un figlio o cambiare lavoro.
La sorveglianza dei consumatori è molto più vecchia di Internet: prima esistevano quattro principali filoni. Il primo, relativo alle aziende che tracciano le abitudini dei propri clienti, ha portato all’utilizzo di sistemi CRM.
Il secondo era il marketing diretto tramite posta cartacea, basato su informazioni demografiche. Il terzo proveniva dagli istituti di credito, che collezionavano dettagli sui propri clienti per vendere le informazioni alle banche per scopi finanziari. Il quarto era relativo al governo e consisteva di diverse informazioni pubbliche: certificati di nascita e di morte, patenti di guida, permessi e licenze, schede elettorali e cosi via. Gli istituti di credito e le aziende di marketing diretto hanno combinato i quattro filoni per diventare i moderni data broker, come Acxiom.
Più dati produciamo, più i data broker li collezionano e sono in condizione di profilarci con maggior accuratezza.
Metadati
Un metadato è un’informazione che descrive un insieme di dati[6], tipicamente utile all’elaborazione di una macchina. I dati sono il contenuto, i metadati sono il contesto: possono rivelare molto più dei dati stessi, soprattutto se aggregati e proiettati su vasta scala.
Come ha detto il General Counsel dell’NSA Stewart Baker, “i metadati ti dicono tutto sulla vita di una persona. Se hai abbastanza metadati, non hai proprio bisogno del contenuto dell’informazione”; il Generale Michael Hayden, ex direttore dell’NSA e della CIA, si è spinto oltre, asserendo che “uccidiamo le persone sulla base dei metadati[7]”.
I tratti caratteristici della personalità possono essere dedotti dalle informazioni relative ai siti web acceduti, così come dall’analisi dei flussi delle chiamate telefoniche e dai dati relativi all’utilizzo delle applicazioni sugli smartphone: i metadati concorrono in maniera determinante alla sorveglianza e al monitoraggio dei comportamenti digitali su Internet.
Il Peccato Originale di Internet
In un famoso articolo pubblicato su Atlantic nel 2014[8], Ethan Zuckerman, direttore del «Center for Civic Media» del MIT, fece pubblica ammenda su quello che chiamò il “Peccato Originale di Internet”. Tale peccato consiste nell’aver contribuito attivamente (Zuckerman è l’ideatore del pop up[9]) al fatto che l’unico modello di business sostenibile di Internet fosse, ed è ancora oggi, la pubblicità.
Siamo stati educati così: per poter usare gratis un servizio Internet (che comporta costi notevoli per poter essere erogato) cediamo dati personali e forniamo informazioni di vario tipo. Siamo spesso ben disposti a cedere dati in cambio di servizi, anche se spesso non si tratta di un processo bilanciato e chiaro. Ne consegue che è materialmente impossibile immaginare un modello di pubblicità on-line che non comporti una forma di sorveglianza degli utenti: più ci apriamo alla sorveglianza, più gli strumenti e i contenuti che vogliamo rimarranno gratuiti.
Secondo Zuckerman ormai l’unico modo per sovvertire l’attuale modello di business è iniziare a pagare i servizi che riteniamo importanti: “è ora di iniziare a pagare per proteggere la nostra privacy, sostenendo i servizi che amiamo e abbandonando quelli che sono completamente gratuiti ma guadagnano solo vendendo le preferenze e le scelte dei loro utenti”[10]. Il modello di business di Internet si fonda quindi sul monitoraggio continuo del comportamento dei propri utenti, altrimenti noto come sorveglianza.
Capitalismo della Sorveglianza e Privacy
Il Capitalismo della Sorveglianza[11] è profondamente innestato nella nostra società sempre più computerizzata e il suo principale obiettivo, semplicemente, è monetizzare i dati acquisiti tramite la sorveglianza. Questo genere di capitalismo[12] porta lo scenario finora analizzato a un livello superiore avvalendosi della manipolazione psicologica nella forma di pubblicità personalizzate per persuaderci a comprare qualcosa o a fare qualcosa (nel caso di Cambridge Analytica, votare per un candidato).
I servizi web che usiamo quotidianamente sono gratuiti perché in cambio cediamo i nostri dati e da questo modello di business ne consegue una proporzionalità diretta tra quantità di dati raccolti e qualità dei servizi erogati: tanto maggiore la pervasività della sorveglianza, tanto migliore l’efficacia dei servizi offerti e della pubblicità associata. In questo scenario lo smartphone è probabilmente il dispositivo tecnologico di sorveglianza più intimo mai realizzato: traccia costantemente la nostra posizione geografica, sa dove viviamo, dove lavoriamo e dove spendiamo il nostro tempo, è la prima e ultima cosa che controlliamo ogni giorno, quindi sa quando ci svegliamo e quando andiamo a dormire. Tutti ne abbiamo almeno uno, quindi sa anche con chi dormiamo.
Nel 2016 l’Unione Europea ha approvato il General Data Protection Regulation (GDPR): il regolamento è ampio e complesso ma alcune prescrizioni sono relative al trattamento dei dati personali dei cittadini dell’Unione Europea, che possono essere collezionati e conservati solamente per “scopi specifici, espliciti e legittimi” e solamente con l’esplicito consenso dell’utente.
Il consenso non può essere seppellito all’interno delle clausole contrattuali dei Termini e delle Condizioni di Utilizzo o espresso in “legalese”; nemmeno può essere dato per scontato fino a quando l’utente non lo esprime esplicitamente. In vista dell’entrata in vigore del GDPR, PayPal ha pubblicato una lista di 600 aziende con cui potrebbe condividere i dati personali dei clienti[13]: che cosa succederà quando ogni azienda dovrà pubblicare questo tipo di informazioni e spiegare esplicitamente come le sta utilizzando?[14] Le risposte collettive riguardano le regole, a livello individuale è possibile prendere decisioni “drastiche” (#DeleteFacebook[15]) e/o adottare una serie di comportamenti online per limitare la raccolta indiscriminata dei propri dati (ci sono numerose guide in merito[16],[17]).
NOTE
- [1] https://en.wikipedia.org/wiki/Microtargeting
- [2] https://www.mturk.com
- [3] https://en.wikipedia.org/wiki/Psychometrics
- [4] http://www.pnas.org/content/110/15/5802
- [5] http://crackedlabs.org/en/corporate-surveillance
- [6] https://en.wikipedia.org/wiki/Metadata
- [7] http://www.nybooks.com/daily/2014/05/10/we-kill-people-based-metadata/
- [8] https://www.theatlantic.com/technology/archive/2014/08/advertising-is-the-internets-original-sin/376041/
- [9] https://en.wikipedia.org/wiki/Pop-up_ad
- [10] http://www.lastampa.it/2014/09/01/tecnologia/il-pop-up-peccato-originale-del-web-SEQsLeovso0OKVeVVlOASN/pagina.html
- [11] https://en.wikipedia.org/wiki/Surveillance_capitalism
- [12] https://www.hbs.edu/faculty/Pages/item.aspx?num=49122
- [13] https://www.paypal.com/ie/webapps/mpp/ua/third-parties-list
- [14] https://www.schneier.com/blog/archives/2018/03/facebook_and_ca.html
- [15] https://www.theguardian.com/technology/2018/mar/23/elon-musk-delete-facebook-spacex-tesla-mark-zuckerberg
- [16] https://motherboard.vice.com/en_us/article/a37m4g/the-motherboard-guide-to-avoiding-state-surveillance-privacy-guide
- [17] https://www.theguardian.com/world/2013/sep/05/nsa-how-to-remain-secure-surveillance
A cura di: Andrea Boggio

Andrea Boggio è Director all’interno della practice Security & Resiliency di Kyndryl con ruolo di responsabile dei Security Customer Advisor.
In precedenza, ha ricoperto ruoli di vendita, prevendita e progettazione di soluzioni e servizi di Cyber e ICT Security.
Ha lavorato presso Global System Integrator (HP, NTT Data) e Telco Provider (Fastweb, Vodafone).
Andrea lavora da 20 anni nell’Information Security Arena e si occupa di diverse aree tematiche, quali: Governance, Risk & Compliance, SOC, Mobile Protection, Threat Management, Network Security.
Detiene le certificazioni professionali ISO/IEC 27001 Lead Auditor, CISA, CISM, CDPSE, CGEIT, CRISC, ITIL e diverse altre legate a specifici vendor di sicurezza.
È membro del capitolo italiano di ISACA e ha partecipato al Cloud Security and Resilience Expert Group di ENISA.Andrea lavora da oltre 15 anni nell’Information Security Arena e si occupa di diverse aree tematiche, quali: Governance, Risk & Compliance, SIEM e SOC, Mobile Protection, Threat e Vulnerability Management, Network Security e Cyber Security.
Detiene le certificazioni professionali ISO/IEC 27001:2013 Lead Auditor, CISA, CISM, CDPSE, CGEIT, CRISC, ITIL e diverse altre legate a specifici vendor di sicurezza. È membro del capitolo italiano di ISACA e ha partecipato al Cloud Security and Resilience Expert Group di ENISA.





